



tf.keras是TensorFlow 2.0的高阶API接口,为TensorFlow的代码提供了新的风格和设计模式,大大提升了TF代码的简洁性和复用性,官方也推荐使用tf.keras来进行模型设计和开发。查看全文>>

我们观察事物时,之所以能够快速判断一种事物(当然允许判断是错误的),是因为我们大脑能够很快把注意力放在事物最具有辨识度的部分从而作出判断,而并非是从头到尾的观察一遍事物后,才能有判断结果,正是基于这样的理论,就产生了注意力机制。查看全文>>

ndarray对象提供了一些可以便捷地改变数组基础形状的属性和方法,例如,将一个3行4列的二维数组转换成6行2列的二维数组,关于这些属性和方法的具体说明如表9-3所示。查看全文>>

交叉验证就是将拿到的训练数据,分为训练和验证集。以下图为例:将数据分成4份,其中一份作为验证集。然后经过4次(组)的测试,每次都更换不同的验证集。即得到4组模型的结果,取平均值作为最终结果。又称4折交叉验证。查看全文>>
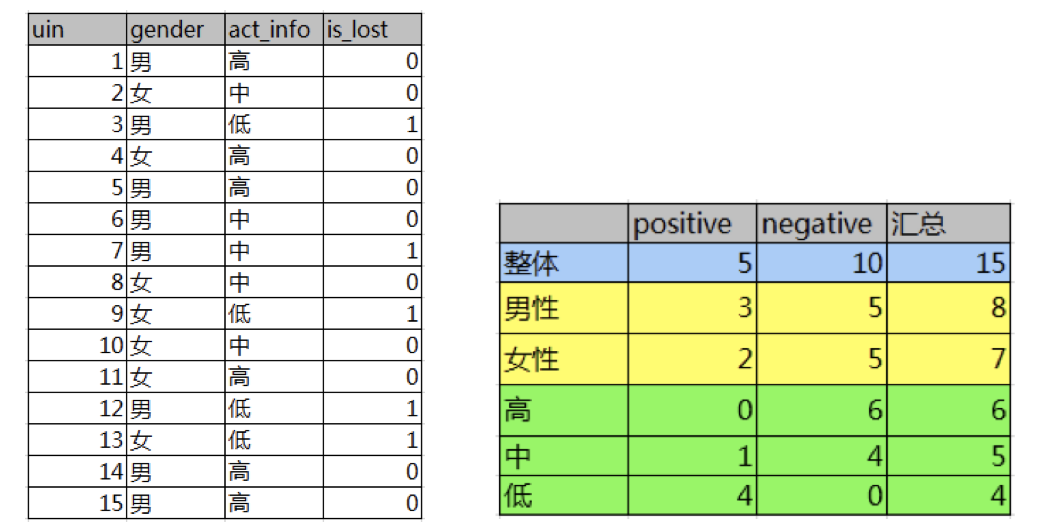
信息增益:以某特征划分数据集前后的熵的差值。熵可以表示样本集合的不确定性,熵越大,样本的不确定性就越大。因此可以使用划分前后集合熵的差值来衡量使用当前特征对于样本集合D划分效果的好坏。查看全文>>
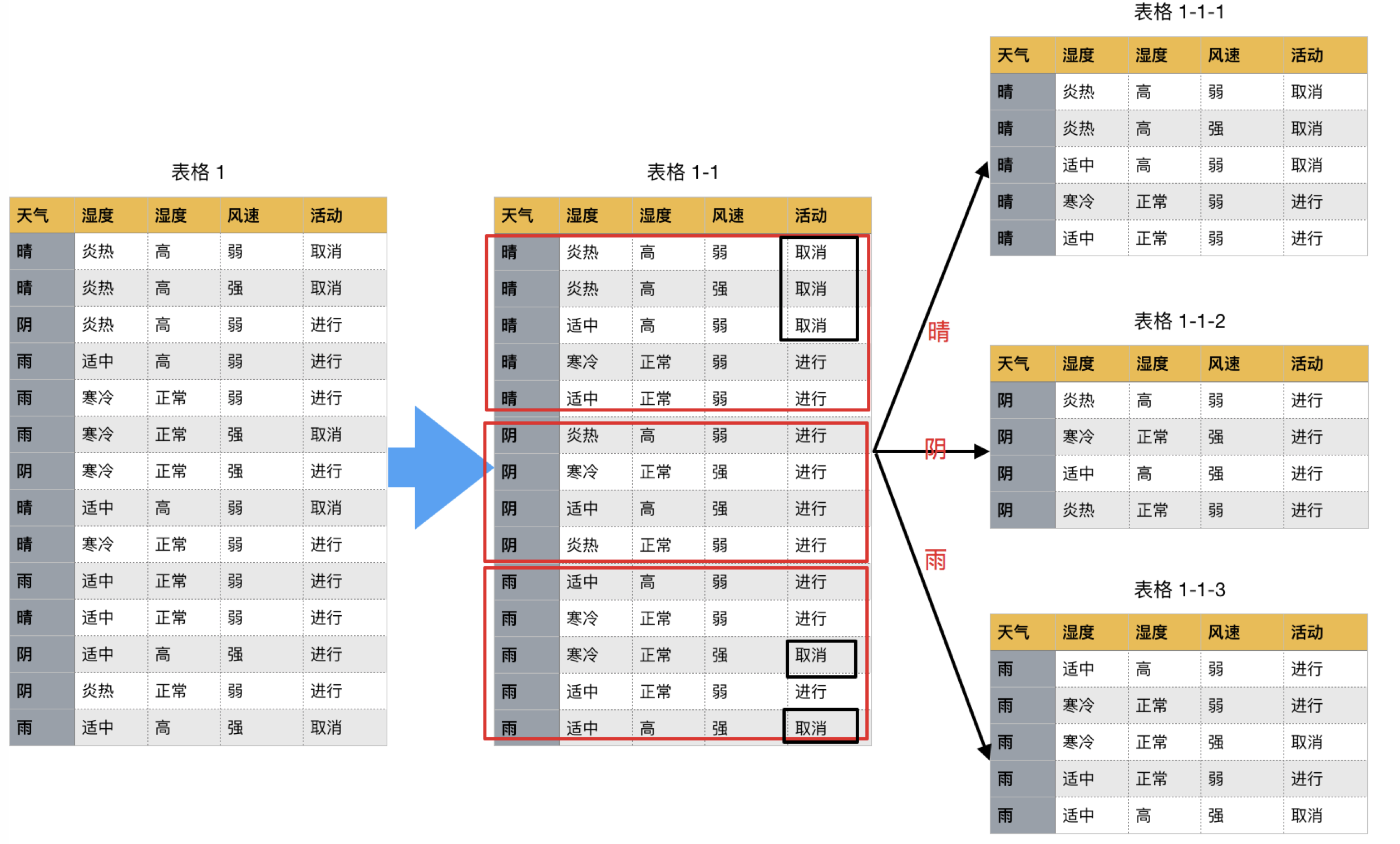
实际上,信息增益准则对可取值数目较多的属性有所偏好,为减少这种偏好可能带来的不利影响,著名的 C4.5 决策树算法 [Quinlan, 1993J 不直接使用信息增益,而是使用"增益率" (gain ratio) 来选择最优划分属性.增益率:增益率是用前面的信息增益Gain(D, a)和属性a对应的"固有值"(intrinsic value) [Quinlan , 1993J的比值来共同定义的。查看全文>>














 AI智能应用开发
AI智能应用开发 AI大模型开发
AI大模型开发 AI鸿蒙开发
AI鸿蒙开发 AI嵌入式+
AI嵌入式+ AI大数据开发
AI大数据开发 AI运维
AI运维 AI测试
AI测试 跨境电商运营
跨境电商运营 AI设计
AI设计 AI视频创作运营
AI视频创作运营














.jpg)