
吃透Agent.jpg)
课程优势.jpg)
课程大厂合作.jpg)
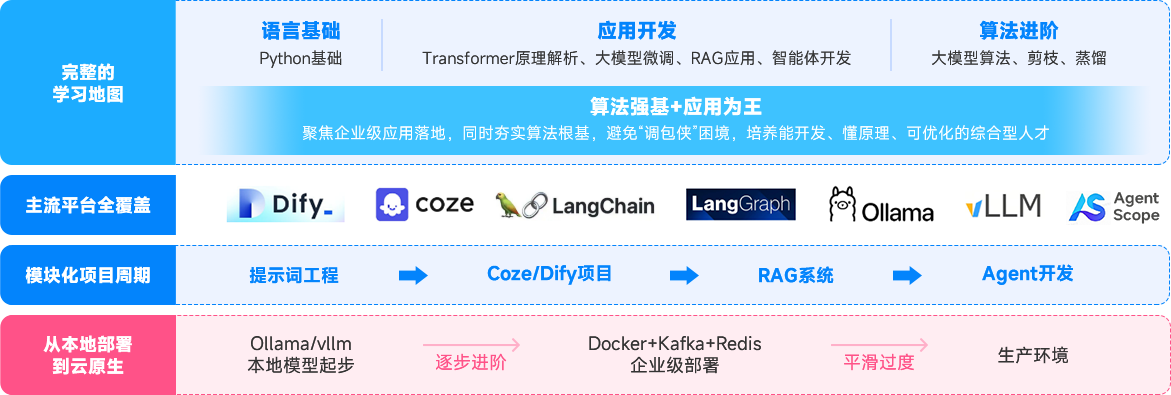






课程介绍
6大
核心技术阶段
大厂
深度合作共建课程
4大
热门就业方向覆盖
10大
多场景实战项目
100天
进阶AI大模型人才
首次就读享优惠价28元
可申请在线试听
研究生学历补贴1000元
985/211本科学历补贴600元
100天打造就业速度快
就业薪资高的AI大模型人才
全国平均就业月薪16016元
最高薪资28000元/月
大模型技术渗透全行业,国内生成式AI用户超7.8亿,产业爆发带来超500万人才缺口
大模型算法稳居热招首位,月薪7万左右,大模型工程师一线城市均薪22K+
17619元
全国班级学生
平均薪资
18856元
一线就业学⽣
平均薪资
14012元
全国应届学⽣
平均薪资

数据来源:脉脉、人社部、职友集及CNNIC公开数据
课程适合人群 有一定数学基础,本科及以上学历,学习效果更佳
没有工作经验,期待学习有前景的AI大模型技术
零基础,对AI人工智能或者大模型感兴趣,有想法致力于通过AI人工智能或AI大模型解决实际业务问题
具备Java、前端、大数据、运维等开发经验,面临职场瓶颈期,期待自我提升
岗位进阶路径多个岗位职等你来
岗位均薪
数据挖掘工程师
机器学习算法工程师
岗位均薪
大模型开发工程师
RAG工程师、Agent工程师
AI工程师、AI应用开发工程师
AI大模型部署工程师
岗位均薪
NLP算法工程师
深度学习算法工程师
知识图谱工程师
CV计算机视觉开发
多模态开发工程师
岗位均薪
大模型算法工程师
大模型推理优化工程师
大模型微调开发
AI架构师
数据来源:职友集/ 智联招聘等行业调研数据
自研企业级OpenClaw框架
构建Agentic Workflow
开发范式与行业趋势对齐
课程教授如何利用OpenClaw理念,让大模型具备“手”和“眼”,自主调用搜案、数据库、API等外部工,构建真正的AgenticWorkflow(智能体工作流)
学员将掌握Prompt Engineering进阶版(Context Management)、AI代码审查、以及多智能体协作管理,成为AI时代的技术指挥官
私有化大模型部署
Python基础语法
基于Ollama+ChatBox实现chatBot
聊天机器人项目实战
能力画像:掌握人工智能Python语言,掌握模型私有化方法,能够通过Python调用私有化部署API实现通用聊天机器人搭建
胜任岗位:初级AI开发工程师
参考薪资:10-12k
Python编程进阶
数据处理与统计分析
Numpy矩阵运算库
Pandas数据处理
提示词工程
智能体开发(Coze)
智能体开发(Dify)
能力画像:利用Python进行数据处理及数据统计分析,通过Coze和Dify构建工作流和智能体开发,快速构建智能体
胜任岗位:数据分析师、Coze开发工程师、Dify开发工程师
参考薪资:10-14k
机器学习
机器学习开发流程
深度学习
深度学习正则化与算法优化
Pytorch框架
NLP技术基础
NLP技术进阶
NLP基础任务
能力画像:掌握机器学习与深度学习核心算法,能够解决基础人工智能问题
胜任岗位:机器学习工程师、深度学习工程师
参考薪资:15-18k
LangChain框架
LangGraph
ChatGLM模型集成
RAG搭建方案
智能体定制开发
RAG项目
智能体定制开发实战项目
多智能体协作
能力画像:通过LangChain和LangGraph框架完成RAG、Agent定制化开发
胜任岗位:Agent开发工程师、RAG开发工程师、智能体全栈开发工程师
参考薪资:18-20k
Transformer原理
迁移学习
大模型微调
模型调优
大模型主流运行机制
大模型微调开发
大模型蒸馏
大模型核心专题
OpenClaw
DeepSeek
DeepSpeed
模型推理优化
能力画像:设计、实现与优化垂直领域大模型
胜任岗位:大模型开发工程师、算法工程师、大模型算法专家、大模型训练/推理开发工程师
参考薪资:20-35k
CV图像分析
多模态大模型
图像生成
文图匹配
扩散模型噪声去除
小程序搭建
全模态大模型
能力画像:通过图像和视频分析、物体识别等技术,实现机器视觉相关任务
胜任岗位:CV算法工程师、图像处理工程师、多模态大模型工程师
参考薪资:20-35k
大模型开发入门
大模型语言进阶
提示词工程
智能体开发(Coze+Dify)
大模型核心开发技术
NewsCompass投满分项目
LangChain框架
大模型RAG项目
智能体项目1(ReAct智能体)
智能体项目2(多智能体)
大模型核心运行机制
大模型微调开发基础及项目
CV图像分析基础
多模态大模型应用开发
主讲内容
本地部署大模型(Ollama)
可视化聊天机器人(ChatBox)
Python核心语法
Python调用大模型API
搭建聊天机器人
可掌握的核心能力
学员能够独立完成大模型本地部署与基础API调用
掌握聊天机器人搭建的核心方法
具备大模型应用开发的基础能力
主讲内容
Python面向对象编程
Python高阶语法(闭包,装饰器、正则、网络编程-Http基础、IP地址、端口)
多任务编程(多任务介绍、 多进程的使用、多线程的使用、线程同步)
MySQL(数据库介绍、MySQL 数据库的安装使用、数据表操作、基本查询操作)
Pandas(Numpy、Pandas的DataFrame、数据清洗、数据读取)
可掌握的核心能力
学员能够熟练运用Python高级特性与多任务编程
掌握数据库操作及数据分析技能
具备开发复杂大模型应用所需的编程能力
主讲内容
提示词介绍及撰写介绍
提示词优化方法
基于Ollama模型部署完成提示词工程案例
基于金融领域的提示词工程项目
可掌握的核心能力
学员能够理解和应用提示词工程原理
掌握优化技巧并完成金融业务场景的实际问题解决
主讲内容
智能体介绍
Coze智能体开发
Coze本地化部署
Coze搭建智能体
【项目】基于Coze的技术面试助手
Docker安装与部署
Dify安装与使用
基于Dify搭建本地知识库
【项目】基于Dify实现Agent开发应用
可掌握的核心能力
【Coze搭建智能体】
掌握 Coze 平台的使用
能够快速从 0 到 1 构建多样化智能体工作流与应用程序
【基于Coze的技术面试助手】
掌握Coze智能体开发范式
能够独立完成多场景智能体应用的构建与部署,实现工作流自动化与业务赋能
【基于Dify实现Agent开发应用】
掌握Dify平台的集成开发与私有化部署
能够完成RAG知识库构建和智能评估Agent的系统搭建
主讲内容
机器学习基础(术语、建模流程、核心框架、评估指标、分类回归聚类基础及案例)
深度学习基础(神经网络基础、激活函数、BP神经网络、RNN循环神经网络、CNN卷积神经网络)
Pytorch框架(Pytorch安装、Pytorch构建神经网络、Pytorch案例实战)
Transformer基础(词向量(Word Embedding)、Transformer(基本原理、实现流程)、
BERT原理及使用、FastText原理及构建流程、BERT优化模型、迁移学习微调)
可掌握的核心能力
掌握大模型所必备的机器学习核心流程
掌握深度学习的核心原理
掌握主流Pytorch深度学习框架
能够完成Bert原理及模型构建
能够完成Transformer原理及模型构建
能够完成GPT系列模型原理及模型构建
主讲内容
随机森林模型
FastText模型
BERT优化
模型量化、剪枝、知识蒸馏
基于大模型文本分类
可掌握的核心能力
掌握商业化文本分类任务的模型选型、优化技巧及多阶段迭代方法
能够具备处理高并发数据分类需求的实战能力
能够完成模型的压缩,包括量化、剪枝、蒸馏
主讲内容
LangChain框架的详解:6大组件应用原理和实现方法
基于本地大模型ChatGLM-6B封装到LangChain框架中
实现LangChain+ChatGLM-6B模型的知识问答系统搭建
可掌握的核心能力
能够完成 LangChain 框架的使用、向量知识库构建及 RAG 系统开发
【基于物流垂直领域的RAG智能问答项目】
能够完成物流领域智能问答系统搭建
掌握RAG项目流程梳理:从本地知识库搭建,到知识检索,模型生成答案等流程介绍
掌握RAG项目数据预处理:本地文档知识分割,向量,存储
主讲内容
【项目】基于职业教育领域RAG智慧问答系统
智能问答系统架构
数据库技术检索
Redis 键值存储与缓存机制
Milvus 向量数据库的架构与检索
Query的意图识别+改写
BERT 分类器的训练与推理
LLM的调用与提示设计
查询分类与动态检索策略的实现
模块化代码设计与代码复用
【项目】基于人力资源场景的RAG的简历推荐系统
文档智能
向量化与索引
检索增强生成
智能代理
配置与 DevOps
可掌握的核心能力
【基于职业教育领域RAG智慧问答系统】
能够掌握 RAG 系统架构设计、数据库技术、检索算法及企业级开发实践
能够完成职业教育智慧问答系统的构建与优化
【基于人力资源场景的RAG的简历推荐系统】
能够掌握文档智能处理、向量化索引、RAG 系统开发及 Agent 框架应用
能够完成可扩展的简历推荐系统部署
主讲内容
Function Call的原理
MCP和Function Call的区别
SSE、AGUI、MCP、A2A协议
基于LangGraph智能体开发
大模型评估
可掌握的核心能力
【InsightScan智扫通Agent项目】
掌握ReAct智能体开发流程
能够完成RAG工具调用
掌握多维度评估系统搭建及生产级服务部署
能够具备构建可迭代优化的C端智能客服系统的能力
主讲内容
实现 MCP 和 A2A 协议
应用LangChain集成 ChatOpenAI,用于 SQL 生成和意图识别
应用Streamlit构建交互式前端,显示聊天历史和 Agent 信息
应用MySQL Connector处理数据库连接和查询,确保数据格式化
应用Uvicorn部署 FastAPI 服务器,支持 MCP 和 A2A 端点
Git、LangGraph、PostgreSQL、大模型、Redis、Kafka、Docker
可掌握的核心能力
【基于A2A的SmartVoyage旅行智能助手】
掌握 A2A 多代理框架开发、意图识别与数据库查询技能
能够完成交互式旅行助手系统的构建。
【基于多场景的Agent智能工单项目】
掌握企业级智能工单系统架构设计
能够实现基于规则过滤、查询改写、意图识别的全流程自动化处理
能够具备复杂业务场景下多智能体系统的开发与运维能力
主讲内容
大模型Transformer架构(词向量(Word Embedding)、Attention注意力机制、Transformer架构、Transformer翻译任务实战 )
大模型迁移学习(预训练模型和微调阶段、NLP中的常用预训练模型(BERT)、Hugging Face预训练模型仓库、Huggingface Transformers库使用、基于微调方式实现NLP任务)
大模型主流模型运行机制(GPT/DeepSeek/QWen基础、架构变化、预训练任务、预训练+微调任务实战)
可掌握的核心能力
大模型Transformer架构:
能够理解 Transformer 的注意力机制与架构设计
掌握基于 Transformer 的翻译任务开发技能
大模型迁移学习:
能够使用 Hugging Face 库对预训练模型进行全量微调
能够完成特定 NLP 任务
大模型主流模型运行机制:
能够理解主流大模型的架构特性与预训练原理
掌握为微调任务选择合适模型的能力
主讲内容
【项目】微博文本信息抽取项目
联合任务数据预处理适配模型训练
实现ChatGLM-6B+LoRA训练
实现ChatGLM-6B+P-Tuning训练
基于Flask框架实现模型API接口开发
【项目】QWen微调文本摘要项目
采用DeepSeed大模型并行计算方式
采用QLora和GPTQ对模型进行量化
采用vLLM和oLLAMA对模型进行部署和推理优化
【项目】基于中医药知识图谱项目
利用爬虫自动采集中药、方剂、功效、症状、疾病等原始文本
使用大语言模型(DeepSeek)+ LangChain 进行实体与关系抽取
构建 Neo4j 图数据库与 Faiss 向量检索双引擎,实现结构化查询与语义匹配
基于 LangGraph 搭建多智能体协同系统,管理复杂问答流程
提供基于 Streamlit 的网页端交互式问答界面
自动生成小红书风格图文内容,并实现一键发布。
可掌握的核心能力
【LoRA微调】微博文本信息抽取项目
能够使用 LoRA 和 P-Tuning 完成多任务微调
掌握数据预处理与线上模型应用开发
【QLoRA微调】QWen微调文本摘要项目
掌握 QLoRA 量化微调与并行计算技术
能够完成文本摘要模型的高效训练与部署
【综合项目】【基于中医药知识图谱项目】
掌握知识图谱构建、多智能体流程调度及生成式应用开发
能够具备垂直领域知识智能化平台的搭建能力
主讲内容
CNN、ResNet原理
Yolo V系列算法
图像分类与分割(Unet、MaskRCNN)
可掌握的核心能力
掌握 CNN、ResNet、Yolo 及分割算法的核心原理
能够具备开发图像分类与目标检测应用的能力
主讲内容
【项目】基于StableDiffusion的图像生成项目
AIGC的详解:AIGC简介,类型,应用场景,产品形态
图像生成算法:GAN;VAE;Diffusion;DALLe;imagen
StableDiffusion详解:Diffusion;latent diffusion;satble diffusion
StableDiffusion实践:模型构建;模型训练;lora;dreambooth;图像生成效果
图像生成小程序搭建:基于stablediffusion构建图像生成的小程序
可掌握的核心能力
【基于StableDiffusion的图像生成项目】
理解 AIGC 与 Diffusion 模型原理
掌握 Stable Diffusion 的模型构建与微调
能够完成图像生成小程序的开发
*课程将会持续更新,更新后所有已报名该课程学员均可免费观看最新课程内容
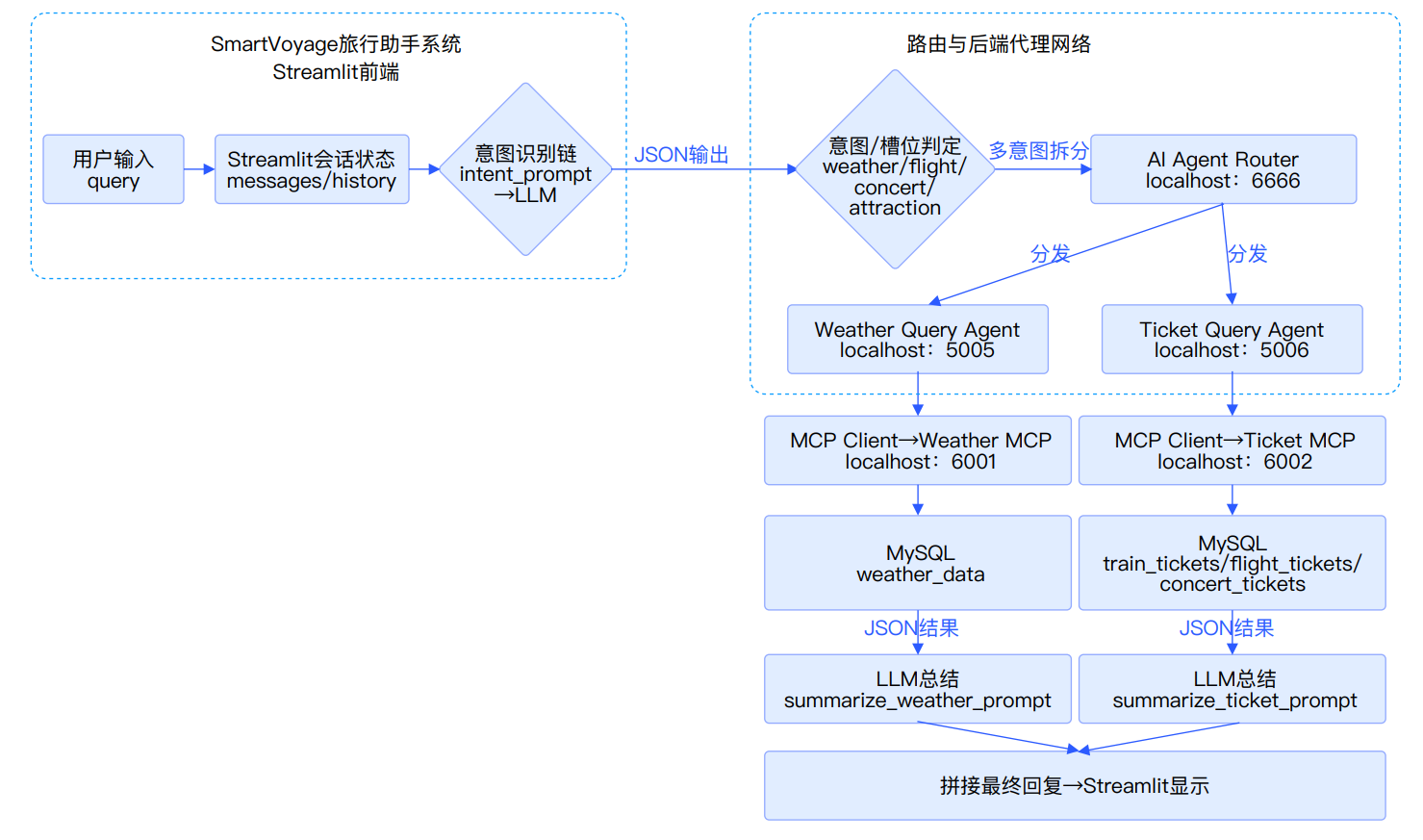
SmartVoyage 是一个智能旅行助手系统,使用 A2A (Agent-to-Agent) 协议构建多代理协作框架,支持用户查询天气和票务信息。系统包括 LLM 路由服务器(意图识别)、天气代理服务器(查询天气数据库)、票务代理服务器(查询票务数据库)、MCP 工具服务器(数据库接口)、数据采集脚本和 Streamlit 前端客户端。用户输入查询(如“北京天气”或“北京到上海火车票”),系统通过 LLM 路由到合适代理,代理生成 SQL 查询 MCP 数据库,返回结果显示在界面。
可掌握的核心能力
掌握 A2A 多代理框架开发
掌握意图识别与数据库查询技能
能够完成交互式旅行助手系统的构建
技术亮点
基于Python-a2a协议实现多代理A2A协作框架
使用LangChain+DeepSeek构建LLM路由服务器意图识别与动态路由
实现MCP工具服务器标准化MySQL查询接口
天气代理服务器LangChain SQL生成与MCP实时天气数据库查询集成
票务代理服务器多类型动态SQL生成与结果友好格式化
基于Streamlit开发A2A多代理实时交互前端客户端
技术架构图
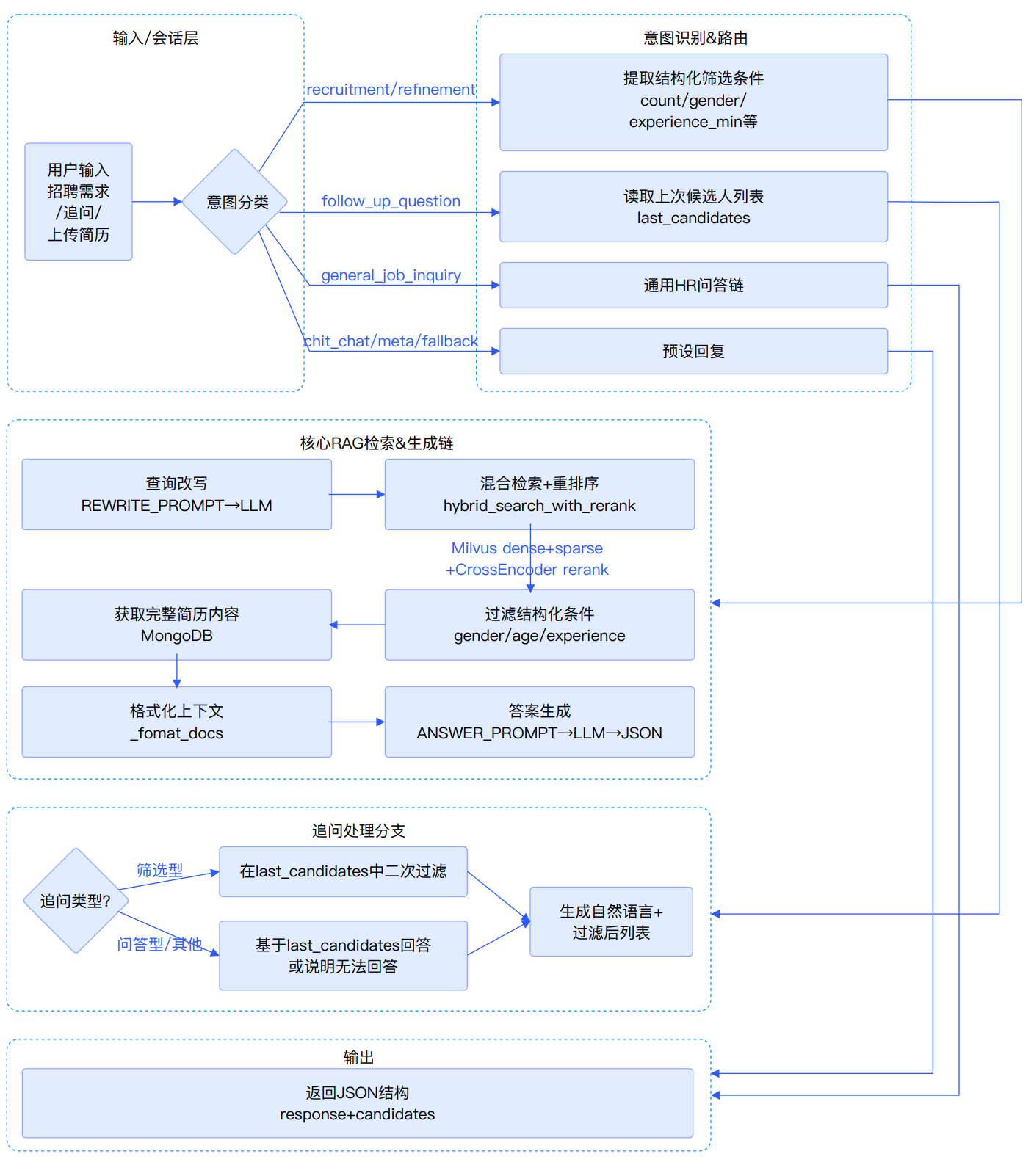
项目基于向量数据库和 LLM 构建一个端到端、可水平扩展的检索增强生成(RAG)系统,支持对异构简历(PDF/DOCX/JPG/PNG)进行自动解析、结构化、语义索引与多轮对话式推荐。系统以向量数据库为核心存储,以 LLM 为推理中枢,以 Agent 框架为调度单元,面向企业 HR 及猎头平台提供秒级、可追溯、可解释的候选人推荐服务。
可掌握的核心能力
掌握文档智能处理、向量化索引
掌握RAG 系统开发及 Agent 框架应用
能够完成可扩展的简历推荐系统部署
技术亮点
基于LangChain+OpenAI实现异构简历(PDF/DOCX/JPG/PNG)智能解析与结构化提取
使用Milvus+BGEM3混合嵌入+ElasticSearch实现高级向量索引与多路召回
构建支持参数过滤、查询重写与历史对话的异步RAG链生成JSON候选人推荐
基于SmartRecruitAgent框架实现意图识别、多轮追问与上下文候选人筛选的智能代理
集成Streamlit前端与Milvus/MongoDB/Elasticsearch多数据库持久化的DevOps配置
使用Ragas框架对RAG系统进行端到端Faithfulness/Answer Relevancy/Context Precision评估优化
技术架构图
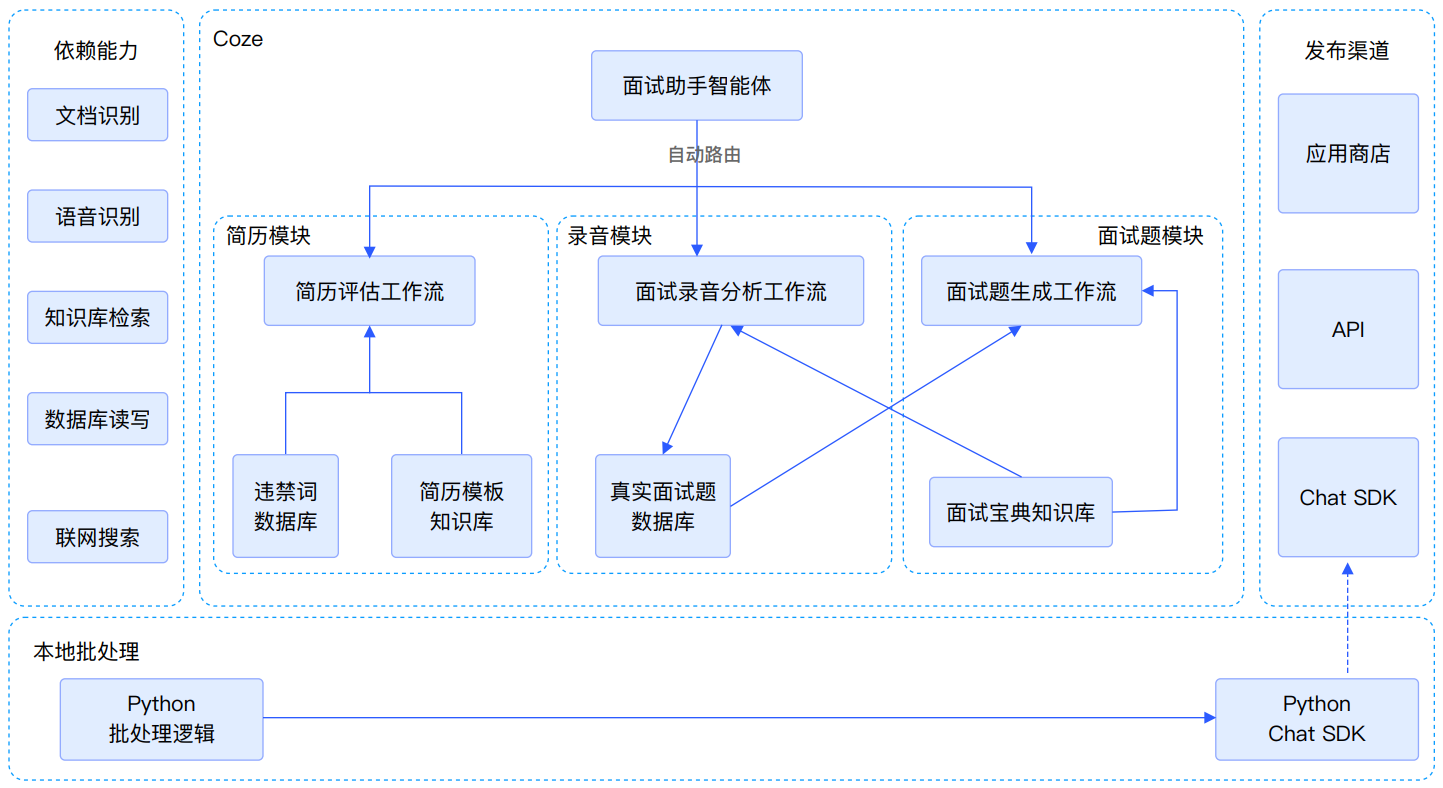
基于Coze工作流平台,结合LLM、ASR、TTS、RAG等技术,为黑马程序员AI学科学生构建面试全流程智能辅助系统,实现简历修改、面试录音分析、个性化面试题生成和实时语音模拟面试等功能。
可掌握的核心能力
掌握Coze智能体开发范式
能够独立完成多场景智能体应用的构建与部署
能够实现工作流自动化与业务赋能
技术亮点
实现基于插件完成PDF、DOCX等文档转文本到分析处理的全流程解决方案
实现基于ASR技术实现录音文件转文本到分析处理的全流程解决方案
实现基于知识库结合PDF实现精准内容生成的解决方案
实现在工作流中读写数据库和知识库的解决方案
实现父子模式多Agent架构自主规划执行解决方案
技术架构图
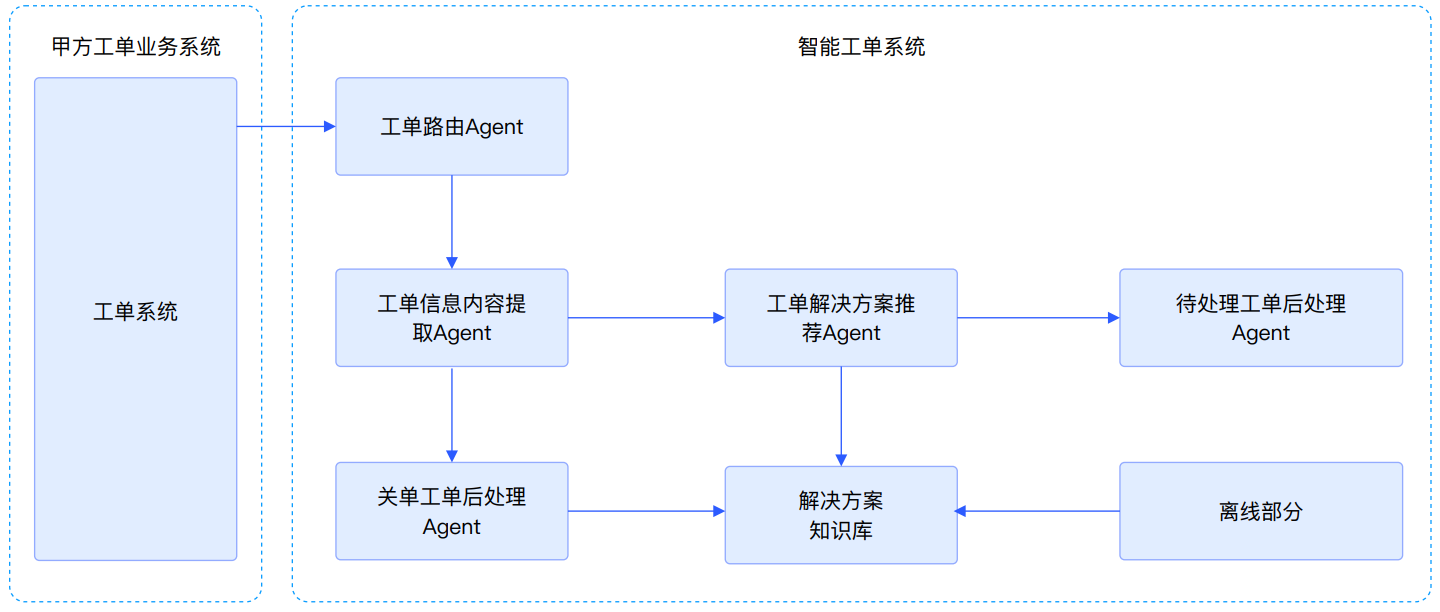
大型ToC企业中的客服团队往往是人力外包,对公司业务细节的了解程度不够,需要和产研团队多次沟通才能完成一次工单的处理,效率低下。 同时,随着AI的发展,工单的处理也可以基于大模型+RAG+funcation call能力进行提效,部分工单自动处理,从而节省部分客服人力资源。 本系统结合大模型能力,融合多种AI技术(RAG+多Agent+MCP)等,结合Kafka消息队列、PostgreSQL向量检索和Docker容器化部署,完成大型企业工单的判定、处理、建议与知识库实时迭代等全流程流转闭环,解决传统客服流程低效问题。
可掌握的核心能力
掌握企业级智能工单系统架构设计
能够实现基于规则过滤、查询改写、意图识别的全流程自动化处理
能够具备复杂业务场景下多智能体系统的开发与运维能力
技术亮点
使用无侵入的方式实时处理业务系统数据的解决方案
实现企业私有化数据脱敏的解决方案
实现基于多层模型实现复杂分类的解决方案
实现基于RAG+MCP调用实现融合知识库+API的上下文工程的解决方案
实现动态更新知识库的解决方案
实现docker镜像构建和服务器部署的企业部署解决方案
技术架构图
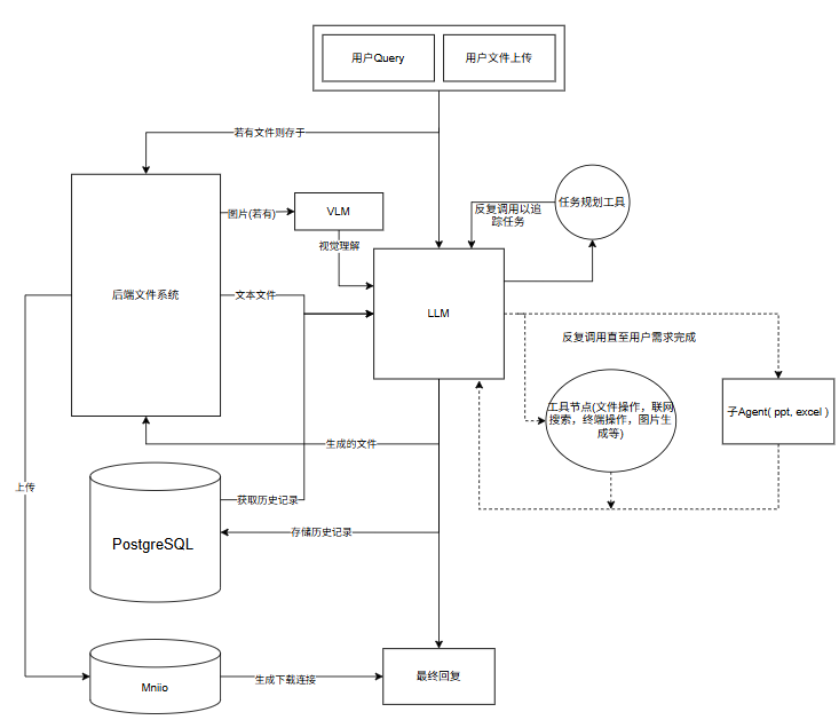
通用智能体作为该领域的高阶形态,其开发能力可为各类垂直场景的智能体构建提供坚实基础与技术范式。本项目基于 Langchain 1.0 框架,集成了 MCP 协议、多模态处理及联网搜索等前沿技术,是理解和构建复杂智能体平台的实战标杆。项目旨在构建一个基于 LangChain 生态的通用 Agent 平台,实现自主任务规划、多模态交互及联网搜索功能,支持多用户并发,具备极强的扩展性。
可掌握的核心能力
构建智能代理中枢:实现工具调用、自主任务规划及深度上下文理解。
实现全模态覆盖:支持主流办公文档(PDF/Word/Excel/PPT)及图片的双向处理。
集成实时信息检索:通过 Tavily API 实现联网搜索,确保信息的时效性与准确性。
提供企业级架构:支持多用户、多会话,提供完善的监控与追踪能力。
技术亮点
先进的技术栈:基于 LangChain v1.0,代表了当前 Agent 开发的主流趋势。
开箱即用的多模态能力:内置对多种办公文档的支持,极大降低了多模态应用的开发门槛。
高度可扩展的架构:模块化设计支持自定义工具、中间件及子代理,方便二次开发。
完善的可观测性:集成 LangSmith,提供全链路的追踪、评估和监控,确保生产环境稳定。
容器化快速部署:支持 Docker & Docker Compose,一键启动,环境一致性高。
技术架构图
基于ChatGLM/QWen+LoRA微调实现微博文本信息抽取+文本分类的多任务,通过一个大模型同时解决多种任务开发和应用,项目基于LLM进行混合任务开发应用的实现,利用ChatGLM/QWen大模型进行P-Tuning微调的方式,基于Flask框架实现API接口开发和应用。
可掌握的核心能力
了解和掌握大语言模型的基本原理和架构,特别是ChatGLM/QWen模型的结构和工作机制。
掌握大模型LoRA微调技术,通过微调预训练的大模型来适应特定任务的需求。
掌握大模型P-Tuning微调技术,对大模型进行高效的参数调整,增强其在特定任务上的表现。
理解和应用多任务学习的概念,通过一个模型同时解决文本信息抽取和文本分类两种任务,提高模型的综合能力和应用效率。
掌握文本信息抽取技术,从非结构化的文本数据中提取有价值的信息,如实体、关系、事件等。
学习文本分类的基本原理和方法,掌握如何将文本数据按照预定义的类别进行归类。
通过Flask框架,学习如何开发和部署API接口,使模型能够通过网络服务被访问和使用。
技术亮点
联合任务数据预处理适配模型训练的解决方案
实现ChatGLM/QWen+LoRA训练的解决方案
实现ChatGLM/QWen+P-Tuning训练的解决方案
基于Flask框架实现模型API接口开发的解决方案
技术架构图
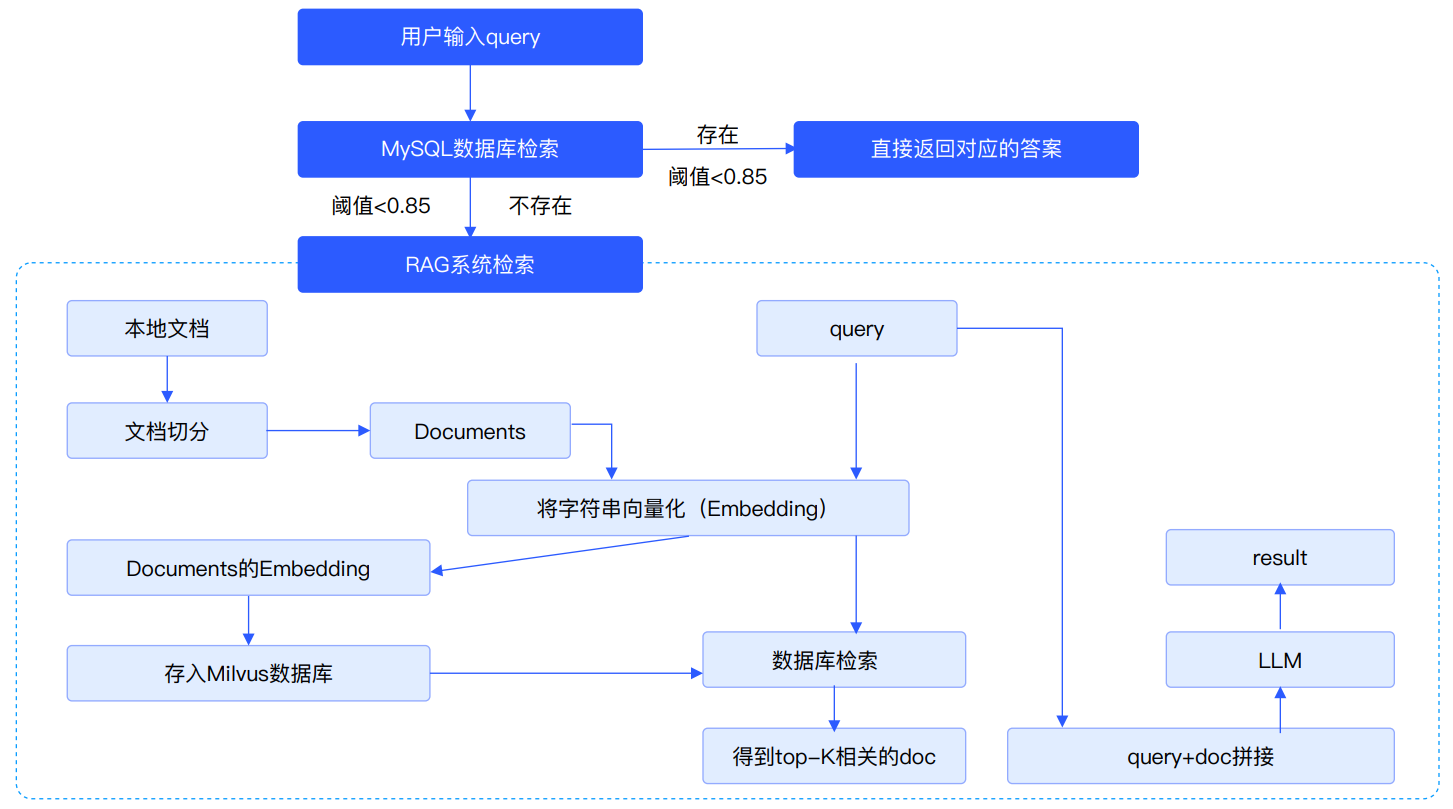
EduRAG 是一个企业级智能问答系统,专为教育场景设计,整合了基于 MySQL 的快速 FAQ 检索和基于 RAG(Retrieval-Augmented Generation)的复杂问题处理能力。系统通过结合 MySQL 数据库的高效查询和 Milvus 向量数据库的语义检索,实现了从常见问题到专业咨询的全方位问答支持。系统支持多来源过滤(如 AI、Java、测试、运维、大数据),并通过 Redis 缓存优化性能,使用 LLM 提供高质量答案生成。
可掌握的核心能力
了解LangChain基本概念、明确LangChain主要组件的作用、了解LangChain常见的使用场景
掌握基于LangChain+ChatGLM-6B模型实现本地知识库的问答实现原理+过程
RAG 系统开发与优化:掌握从数据分片到答案生成的 RAG 全流程,熟练应用 HyDE、子查询等检索增强策略提升系统性能。
大模型应用实践:能够集成 LLM(如 OllamaLLM)并设计高效 Prompt,解决知识问答中的业务定制化需求。
智能查询路由设计:实现规则、相似度和 LLM 三层路由,精准分发查询并优化复杂意图识别效率。
后端服务与前端开发:使用 FastAPI 开发高并发 API 并通过 Gradio 构建交互界面,满足企业级服务与用户体验要求。
数据处理与多源集成:熟练处理结构化与非结构化数据,结合 MySQL 和向量搜索打造高效知识检索系统。
企业级问题解决能力:通过日志调试和高并发设计,具备定制化开发与性能优化的实战技能,适配智能客服等场景。
技术亮点
数据库查询优化:BM25 + Redis 缓存
语义检索:Milvus 混合向量检索
查询分类:BERT 分类器
动态检索策略:LLM 驱动的策略选择(直接检索、HyDE、子查询、回溯)
答案生成:LLM + RAG 提示模板
性能优化:Redis 缓存 + 模块化设计
日志与监控:统一日志系统(logging)
配置管理:ConfigParser + config.ini
技术架构图
北京化工大学硕士
算法专家
曾任大厂核心业务专家
字节跳动、滴滴出行
韩国世翰大学
情报学硕士
加州大学尔湾分校博士
前Meta定量数据科学家
北京大学工学硕士
《深度学习理论与实践》
中国科学院大学理学博士
曾在美企任高级工程师
工学硕士,主导研发多项
国家和省级科研项目
北京航空航天大学
聚焦自然语言处理算法
天津大学工学硕士,擅长
从零构建深度学习预测模型


全日制教学管理每天10小时专属学习计划
测试、出勤排名公示
早课+课堂+辅导+测试+心理疏导

实战项目贯穿教学一线大厂实战项目
实用技术全面覆盖
课程直击企业需求

AI教辅保障学习效果水平测评,目标导向学习
随堂诊断纠错,阶段测评
在线题库,BI报表数据呈现

个性化就业指导就业指导课,精讲面试题
模拟面试,给出就业建议
试用期辅导,帮助平稳过渡

持续助力职场发展免费享,更新项目和学习资料
主题讲座,获取行业前沿资讯
人脉经验,线下老学员分享会

无忧学就业权益未就业,全额退费
薪资低于标准,发放补贴
多一份安心,学习无忧

核心技术阶段
深度合作共建课程
热门就业方向覆盖
多场景实战项目
进阶AI大模型人才
能力画像:掌握大模型私有化部署及人工智能Python语言,从零搭建聊天机器人,开启AI实战第一步。
胜任岗位:初级大模型开发工程师
能力画像:利用Python进行数据处理及数据统计分析,同时通过Coze和Dify构建工作流和智能体开发,快速构建智能体。
胜任岗位:数据分析师、Coze开发工程师、Dify开发工程师
能力画像:掌握机器学习、深度学习与NLP核心算法,能够解决模型构建和训练关键问题。
胜任岗位:机器学习工程师、深度学习工程师、算法工程师
能力画像:通过LangChain和LangGraph框架完成RAG、Agent定制化开发。
胜任岗位:Agent开发工程师、RAG开发工程师、智能体全栈开发工程师
能力画像:设计、实现与优化垂直领域大模型;通过图像和视频分析等技术,实现机器视觉相关任务
胜任岗位:算法工程师、大模型训练/推理开发工程师、CV算法工程师、图像处理工程师、深度学习工程师
课程大纲
入门试学班
1. 大模型开发入门
高手班
1. 大模型语言进阶 2. 提示词工程 3. 智能体开发(Coze+Dify) 4. 智能体开发(Coze+Dify)项目 5. 大模型核心开发技术 6. NewsCompass投满分项目 7. LangChain框架 8. RAG项目 9. 智能体项目1(ReAct智能体) 10. 智能体项目2(多智能体) 11. 大模型核心运行机制 12. 大模型微调开发基础及项目 13. CV图像分析基础 14. 多模态大模型应用开发
AI大模型开发V6.5版本
课时:8天 技术点:60项 测验:1次 学习方式:线下面授
01_掌握搭建聊天机器人的步骤| 02_掌握搭建聊天机器人必备语言和工具| 03_掌握大模型必备Python语言的基本语法| 04_掌握分支结构的用法| 05_掌握循环结构的用法| 06_掌握容器类型相关的概述| 07_掌握字符串的相关操作| 08_掌握容器类型的遍历 | 09_掌握列表-字典的相关操作| 10_掌握函数的各种参数| 11_掌握函数的引用相关| 12_独立完成匿名函数的编写和使用| 13_掌握文件的相关操作| 14_掌握异常的处理方式| 15_熟悉Streamlit框架搭建页面
1. AI大模型入门与应用零基础入门AI大模型开发的开始,包含了以下技术点:
01_AI大模型项目介绍和环境搭建:AI大模型搭建聊天机器人需求分析;AI大模型搭建聊天机器人步骤和流程;AI大模型搭建聊天机器人必备语言和工具项目环境搭建| 02_AI大模型入门与应用:通用AI大模型和垂直领域大模型应用实操,包括AI赋能办公、运营、文生图多模态等多种应用场景,帮助学生熟悉AI大模型行业落地场景,为后续开发提供支持
2. 大模型必备Python基础语法掌握大模型必备Python基础语法,包含了以下技术点:
01_学习大模型必备Python语言| 02_Python解释器和Pycharm开发工具安装| 03_注释和定义变量| 04_标识符和关键字以及命名规范| 05_输入和输出函数| 06_算数运算,比较运算,逻辑运算,赋值运算
3. 大模型必备Python控制语句掌握大模型必备Python控制语句,包含了以下技术点:
01_分支语句 if elif else| 02_循环结构 while for| 03_跳转语句 break 和 continue
4. 大模型必备Python容器掌握大模型必备Python容器,包含了以下技术点:
01_循环嵌套-99乘法表| 02_循环案例-猜数字游戏| 03_不同容器的介绍和定义| 04_索引操作| 05_切片操作| 06_字符串的常见功能| 07_容器的遍历| 08_列表详解| 08_元组详解| 10_字典容器的使用| 11_容器类型嵌套案例-随机分配办公室| 12_容器类型-公共的运算符和方法
5. 大模型必备Python函数掌握大模型必备Python函数,包含了以下技术点:
01_函数入门| 02_函数的参数和返回值| 03_变量作用域| 04_函数的多种参数| 05_拆包和变量交换| 06_引用和匿名函数| 07_递归实操 【综合案例】斐波那契数列
6. 大模型必备Python文件和异常处理掌握大模型必备Python文件和异常处理,包含了以下技术点:
01_文件的读写入门| 02_中文乱码和路径问题| 03_文件复制| 04_os模块| 05_with-open语法| 06_异常处理方式| 07_导入包和模块
7. 基于Streamlit+LangChain搭建智能聊天机器人掌握Python调用大模型API的能力,包含了以下技术点:
01_Streamlit框架| 02_LangChain框架组成和开发流程| 03_通义百炼大模型平台| 04_通义大模型API调用
课时:8天 技术点:80项 测验:1次 学习方式:线下面授
01_掌握面向对象编程思想| 02_独立运用面向对象思想完成指定需求| 03_掌握深拷贝和浅拷贝代码原理| 04_独立完成面向对象版-学生管理系统| 05_掌握闭包, 装饰器的用法| 06_独立完成网编案例代码实现| 07_掌握多进程, 多线程相关代码实现| 08_掌握上下文管理器对象的使用| 09_掌握生成器, 迭代器的用法| 10_理解正则表达式的相关运用| 11_掌握MySQL基本操作| 12_掌握Pandas基本操作
1. Python面向对象进阶从逐步建立起面向对象编程思想,再到会使用对象,到创建对象,再到真正理解为什么封装对象。包含了以下技术点:
01_面向对象入门:面向对象和面向过程;类和对象的区别;定义类和属性;定义方法和魔法方法;面向对象-案例;【实战案例】面向对象综合实战案例| 02_面向对象进阶:继承的使用;私有权限;类属性和对象属性;类方法和静态方法;面向对象版 -学生管理系统;【实战作业】面向对象版-学生管理系统(采取部分实战)
2. Python高阶语法主要学习Python高阶语法,包含了以下技术点:
01_闭包+装饰器:深拷贝, 浅拷贝详解;闭包详解;装饰器详解;【实战案例】装饰器实战案例| 网编+多进程入门:网编相关概述介绍;网编案例-客户端发送文件到服务器端;并行和并发详解;多进程-代码实现;【实战案例】网编案例-客户端和服务器端交互 02_多线程详解:多线程代码实现;守护线程详解;互斥锁详解;线程同步详解;上下文管理器详解| 03_Json数据文件读取和处理;【实战案例】Json数据文件读取和处理| 04_生成器,正则详解:生成器详解;迭代器详解;正则表达式详解;【实战案例】正则表达式文本匹配综合案例
3. MySQL主要学习MySQL数据库的核心知识,包含了以下技术点:
01_数据库介绍、MySQL 数据库的安装使用:数据库基本操作;数据库概念和作用;MySQL数据类型;数据完整性和约束| 02_数据表操作:数据库;表操作命令;表数据操作命令| 03_基本查询操作:where子句;分组聚合;连接查询;外键的使用;PyMySQL
4. Pandas主要学习Pandas核心知识,包含以下技术点:
01_Numpy:Numpy基础概念与操作;运算优势;数组的属性;数组的形状;Numpy实现数组基本操作| 02_Pandas的DataFrame、数据清洗、数据读取:Pandas统计分析;Pandas数据整理;Pandas透视表;Pandas可视化
课时:2天技术点:20项测验:1次学习方式:线下面授
01_能够理解和应用提示词工程原理| 02_掌握优化技巧并完成金融业务场景的实际问题解决

基于Zero-shot零样本学习能力,通过DeepSeek/QWen/ChatGLM模型对金融领域数据进行分类、信息抽取、文本匹配,更好的解决业务问题。
01_提示词撰写解决方案| 02_文本分类提示词解决方案| 03_信息抽取提示词解决方案| 04_文本匹配提示词解决方案
1. 什么是Prompt Engineering| 2. Prompt Engineering的原理以及实际应用的优化技巧| 3. 如何利用Prompt Engineering完成实际金融业务
课时:1天 技术点:20项 测验:1次 学习方式:线下面授
01_能够掌握 Coze 平台的使用| 02_掌握快速从 0 到 1 构建多样化智能体工作流与应用程序| 03_掌握Coze智能体开发范式| 04_能够掌握Dify平台的集成开发与私有化部署
1. 智能体开发(Coze)主要学习Coze核心操作,包含了以下技术点:
01_智能体介绍| 02_Coze智能体开发| 03_Coze本地化部署
2. 【案例】Coze搭建智能体基于Coze搭建智能体,快速从0到1搭建工作流和应用程序,包含了以下技术点:
01_案例:智能问答助手| 02_案例:旅游规划小精灵| 03_案例:智能助教| 04_案例:智能面试官| 05_案例:口语练习专家 案例讲2练3
3. 【项目】基于Coze的技术面试助手基于Coze工作流,为黑马程序员AI学科学生临近毕业时面试相关的问题进行提效。结合LLM、ASR、TTS、RAG等技术,为面试中常见的效率痛点赋能,代替部分人工,缓解教师压力,包含了以下技术点:
01_简历修改:基于OCR插件、prompt、数据库查询,实现简历中各类常见问题的召回和修改建议。 以及进阶功能:违禁词过滤、业务背景重复率统计等。辅助学生编写更好的简历| 02_面试录音分析:基于多模态大模型实现ASR,基于prompt实现面试官、应试者角色划分,最终实现文字提取、摘要以及建议,提面试高录音分析的效率| 03_面试题生成:基于黑马面试宝典使用RAG技术结合学生的简历,结合简历上的技能点、业务背景、毕业时间、专业等信息,生成个性化的面试题题库| 04_模拟面试:基于简历和面试题生成流水线等功能,基于老师音色克隆面试官音色,结合ASR模型、TTS模型等技术,实现实时语音面试
4. 智能体开发(Dify)主要学习Dify核心操作,包含了以下技术点:
01_Docker安装与部署| 02_Dify安装与使用| 03_基于Dify搭建本地知识库
5. 【项目】基于Dify实现Agent开发应用项目基于Ollama私有化部署DeepSeek R1:8b模型;基于Docker结合Dify大模型应用开发平台构建可视化聊天界面,包含了以下技术点:
01_大模型私有化部署:Ollama、DeepSeek/QWen| 02_聊天机器人搭建:基于Dify搭建可视化聊天机器人| 03_RAG构建:基于Dify搭建本地知识库| 04_Agent智能体构建:基于Dify搭建Agent智能体
6. 智能体平台开发实战【实战】多业务场景项目实战,包含了以下技术点:
01_多业务场景项目实战
课时:3天学习方式:线下面授
基于Coze的技术面试助手项目
基于Dify实现Agent开发应用项目

基于Coze工作流平台,结合LLM、ASR、TTS、RAG等技术,为黑马程序员AI学科学生构建面试全流程智能辅助系统,实现简历修改、面试录音分析、个性化面试题生成和实时语音模拟面试等功能。
01_能够掌握Coze智能体开发范式| 02_能够独立完成多场景智能体应用的构建与部署| 03_能够实现工作流自动化与业务赋能
01_实现基于插件完成PDF、DOCX等文档转文本到分析处理的全流程解决方案| 02_实现基于ASR技术实现录音文件转文本到分析处理的全流程解决方案| 03_实现基于知识库结合PDF实现精准内容生成的解决方案| 04_实现在工作流中读写数据库和知识库的解决方案| 05_实现父子模式多Agent架构自主规划执行解决方案
01_简历修改:基于OCR插件、prompt、数据库查询,实现简历中各类常见问题的召回和修改建议。 以及进阶功能:违禁词过滤、业务背景重复率统计等。辅助学生编写更好的简历| 02_面试录音分析:基于多模态大模型实现ASR,基于prompt实现面试官、应试者角色划分,最终实现文字提取、摘要以及建议,提面试高录音分析的效率| 03_面试题生成:基于黑马面试宝典使用RAG技术结合学生的简历,结合简历上的技能点、业务背景、毕业时间、专业等信息,生成个性化的面试题题库| 04_模拟面试:基于简历和面试题生成流水线等功能,基于老师音色克隆面试官音色,结合ASR模型、TTS模型等技术,实现实时语音面试

基于Docker部署Dify平台,结合Ollama私有化模型与RagFlow构建企业级评估智能体,实现知识库管理、可视化聊天界面及Agent系统开发。
01_能够掌握Dify平台的集成开发与私有化部署| 02_能够完成RAG知识库构建和智能评估Agent的系统搭建
01_项目基于Ollama私有化部署DeepSeek R1:8b模型| 02_基于Docker结合Dify大模型应用开发平台构建可视化聊天界面
01_大模型私有化部署:Ollama、DeepSeek/QWen| 02_聊天机器人搭建:基于Dify搭建可视化聊天机器人| 03_RAG构建:基于Dify搭建本地知识库| 04_Agent智能体构建:基于Dify搭建Agent智能体
课时:10天 技术点:70项 测验:1次 学习方式:线下面授
01_能够掌握机器学习和深度学习核心基础| 02_能够完成 Bert及GPT核心Transformer架构分类的使用| 03_能够完成分类模型基础搭建
1. 机器学习基础该部分主要学习机器学习基础,包含以下技术点:
01_术语| 02_建模流程| 03_核心框架| 04_评估指标| 05_分类算法/回归算法/聚类算法基础及案例
2. 深度学习该部分主要学习深度学习,包含以下技术点:
01_Pytorch框架| 02_Pytorch安装| 03_Pytorch构建神经网络| 04_Pytorch案例实战
3. NLP核心技术该部分主要学习NLP核心技术,包含以下技术点:
01_词向量(Word Embedding)| 02_Transformer(基本原理、实现流程)| 03_BERT原理及使用| 04_FastText原理及构建流程| 05_BERT优化模型| 06_迁移学习微调
课时:7天技术点:100项测验:1次学习方式:线下面授
01_基于大规模业务留存数据构建快速文本分类系统| 02_快速搭建短文本精准分类模型| 03_基于随机森林和FastText搭建快速基线模型, 验证业务通道的能力| 04_基于BERT的迁移学习优化模型搭建的能力| 05_实现神经网络量化的优化与测试| 06_实现神经网络剪枝的优化与测试| 07_实现神经网络知识蒸馏的优化与测试| 08_更多主流预训练模型的优化与深度模型剖析| 09_BERT模型在生成式任务和工程优化上的深入扩展

NewsCompass投满分项目是结合今日头条真实场景下的海量数据, 快速搭建随机森林和FastText的基线模型, 以验证商业化落地的可行性. 更多聚焦在深度学习的优化方法上, 搭建基于BERT的初版微调模型, 应用量化,剪枝,预训练模型微调,知识蒸馏等多种手段,反复迭代,反复优化模型的离线效果,在线效果。
01_海量文本快速分类基线模型解决方案| 02_基于预训练模型优化的解决方案| 03_模型量化优化的解决方案| 04_模型剪枝优化的解决方案| 05_模型知识蒸馏优化的解决方案| 06_主流迁移学习模型微调优化的解决方案
01_随机森林(集成学习)| 02_基线模型(FastText)| 03_BERT优化| 04_模型量化、剪枝、知识蒸馏| 05_基于大模型文本分类|
课时:2天技术点:80项测验:0次学习方式:线下面授
01_掌握LangChain工具的基本使用方法,了解如何通过LangChain构建和管理语言模型应用| 02_熟悉ChatGLM-6B模型的应用,了解如何将大语言模型与本地知识库结合,实现高效准确的问答功能| 03_理解向量知识库的基本概念和技术原理,掌握如何构建和使用向量知识库来存储和检索知识信息| 04_掌握知识库的构建方法,从数据采集、处理到存储,学习如何将电商物流相关信息整合到知识库中| 05_理解RAG系统的基本原理和实现方法,学习如何结合检索和生成技术,提升问答系统的准确性和实用性| 06_从零开始搭建一个问答机器人,掌握整个系统的设计、实现和部署过程

基于物流垂直领域的RAG智能问答项目基于LangChain+Qwen/DeepSeek/ChatGLM-6B实现电商物流本地知识库问答机器人搭建,让模型根据本地信息进行准确回答,解决大模型的“幻觉”问题,实现精准问答。通过项目皆在掌握LangChain工具的基本使用方式,理解向量知识库以及实现知识库的技术原理, 快速构建检索增强生成(RAG)系统。
01_LangChain工具使用介绍解决方案| 02_ChatGLM-6B模型集成到问答系统中的解决方案| 03_向量知识库的构建和检索的解决方案| 04_搭建RAG系统的解决方案
01_项目介绍:理解什么是RAG系统| 02_项目流程梳理(从本地知识库搭建,到知识检索,模型生成答案等流程介绍)| 03_数据预处理:本地文档知识分割,向量,存储| 04_LangChain框架的详解讲解:6大组件应用原理和实现方法| 05_基于本地大模型ChatGLM-6B封装到LangChain框架中| 06_实现LangChain+ChatGLM-6B模型的知识问答系统搭建
课时:8天学习方式:线下面授
基于职业教育领域RAG智慧问答系统项目
基于人力资源场景的RAG的简历推荐系统项目

基于IT职业教育行业答疑大模型抽取RAG解决方案,通过项目学习完成企业级RAG系统完整流程搭建与测试及优化。从智能查询路由设计、数据处理与多源集成、模型微调到后端服务与前端开发完成全栈RAG系统构建。
01_了解LangChain基本概念、明确LangChain主要组件的作用、了解LangChain常见的使用场景| 02_掌握基于LangChain+ChatGLM-6B模型实现本地知识库的问答实现原理+过程| 03_RAG系统开发与优化:掌握从数据分片到答案生成的RAG全流程,熟练应用 HyDE、子查询等检索增强策略提升系统性能| 04_大模型应用实践:能够集成 LLM(如 OllamaLLM)并设计高效 Prompt,解决知识问答中的业务定制化需求| 05_智能查询路由设计:实现规则、相似度和 LLM 三层路由,精准分发查询并优化复杂意图识别效率| 06_后端服务与前端开发:使用 FastAPI 开发高并发 API 并通过 Gradio 构建交互界面,满足企业级服务与用户体验要求| 07_数据处理与多源集成:熟练处理结构化与非结构化数据,结合 MySQL 和向量搜索打造高效知识检索系统| 08_企业级问题解决能力:通过日志调试和高并发设计,具备定制化开发与性能优化的实战技能,适配智能客服等场景
01_数据库查询优化:BM25 + Redis 缓存解决方案| 02_语义检索:Milvus 混合向量检索解决方案| 03_查询分类:BERT 分类器解决方案| 04_动态检索策略:LLM 驱动的策略选择解决方案| 05_答案生成:LLM + RAG 提示模板解决方案| 06_性能优化:Redis 缓存 + 模块化设计解决方案| 07_日志与监控:统一日志系统(logging)解决方案| 08_配置管理:ConfigParser + config.ini解决方案
01_智能问答系统架构:FAQ 系统与 RAG 系统的区别与应用场景| 02_数据库技术:MySQL 表查询;Redis 键值存储与缓存机制;Milvus 向量数据库的架构与索引类型| 03_检索算法:BM25 算法原理;密集向量 & 稀疏向量混合检索;重排序的作用| 04_query的意图识别+改写:BERT 分类器的训练与推理;LLM的调用与提示设计;查询分类与动态检索策略的实现逻辑| 05_企业级开发实践:模块化代码设计与代码复用;配置文件(config.ini)与环境变量管理;日志系统设计与错误处理

项目基于向量数据库和 LLM 构建一个端到端、可水平扩展的检索增强生成(RAG)系统,支持对异构简历(PDF/DOCX/JPG/PNG)进行自动解析、结构化、语义索引与多轮对话式推荐。系统以向量数据库为核心存储,以 LLM 为推理中枢,以 Agent 框架为调度单元,面向企业 HR 及猎头平台提供秒级、可追溯、可解释的候选人推荐服务。
01_能够掌握文档智能处理、向量化索引、RAG 系统开发及 Agent 框架应用| 02_能够完成可扩展的简历推荐系统部署。
01_基于LangChain+OpenAI实现异构简历(PDF/DOCX/JPG/PNG)智能解析与结构化提取| 02_使用Milvus+BGEM3混合嵌入+ElasticSearch实现高级向量索引与多路召回| 03_构建支持参数过滤、查询重写与历史对话的异步RAG链生成JSON候选人推荐| 04_基于SmartRecruitAgent框架实现意图识别、多轮追问与上下文候选人筛选的智能代理| 05_集成Streamlit前端与05_Milvus/MongoDB/Elasticsearch多数据库持久化的DevOps配置| 06_使用Ragas框架对RAG系统进行端到端Faithfulness/Answer Relevancy/Context Precision评估优化
01_文档智能| 02_向量化与索引| 03_检索增强生成| 04_智能代理| 05_配置与 DevOps
课时:5天技术点:100项测验:0次学习方式:线下面授
01_能够掌握ReAct智能体开发流程| 02_能够完成RAG工具调用、多维度评估系统搭建及生产级服务部署| 03_能够具备构建可迭代优化的C端智能客服系统的能力

项目是一个面向消费者(toC)的智能客服系统,旨在为用户提供全周期的扫地机器人相关服务并根据用户使用习惯生成使用报告,为用户提供使用优化建议。该系统基于RAG技术及ReAct框架构建,涵盖产品咨询、使用报告生成与优化建议。通过一个统一的Agent界面,为用户提供高效、准确且个性化的支持,提升用户体验与满意度,结合三位一体评估体系和Flask/Streamlit部署实现商业化落地。
01_基于ReAct框架实现的Agent| 02_RAG工具实现本地知识库构建| 03_Prompt Engineering实现用户使用报告的生成| 04_Flask的模型部署| 05_基于Streamlit的前端服务构建
01_数据来源:扫地机器人的产品手册及相关知识库(基础与技术类、产品功能类、智能交互类、维护与保养类、选购指南类、使用技巧类、配件与耗材类、安全与隐私类、特殊场景类等问题)| 02_基于ReAct框架实现的Agent,包括推理(Reasoning)模块以及行动(Acting)模块| 03_使用RAG工具实现本地知识库构建。(文档读取模块、向量数据库模块、RAG工具调用模块)| 04_使用大模型Deepseek v3结合Prompt Engineering实现用户使用报告的生成| 05_构建三位一体评估体系,针对检索内容(Precision、Recall、mrr)、生成内容(ROUGE-1、ROUGE-L、BERTScore、Faithfulness)、总性能(平均延时、QPS)| 06_构建日志打印模块,重点监控工具的运行情况。(控制台日志+生产环境日志)| 07_基于Flask的模型部署(服务端+客户端)、基于Streamlit的前端服务
课时:5天学习方式:线下面授
基于A2A的SmartVoyage旅行智能助手
基于多场景的Agent智能工单项目

SmartVoyage 是一个智能旅行助手系统,使用 A2A (Agent-to-Agent) 协议构建多代理协作框架,支持用户查询天气和票务信息。系统包括 LLM 路由服务器(意图识别)、天气代理服务器(查询天气数据库)、票务代理服务器(查询票务数据库)、MCP 工具服务器(数据库接口)、数据采集脚本和 Streamlit 前端客户端。用户输入查询(如“北京天气”或“北京到上海火车票”),系统通过 LLM 路由到合适代理,代理生成 SQL 查询 MCP 数据库,返回结果显示在界面。
01_能够掌握 A2A 多代理框架开发、意图识别与数据库查询技能 02_能够完成交互式旅行助手系统的构建
01_基于Python-a2a协议实现多代理A2A协作框架| 02_使用LangChain+DeepSeek构建LLM路由服务器意图识别与动态路由| 03_实现MCP工具服务器标准化MySQL查询接口| 04_天气代理服务器LangChain SQL生成与MCP实时天气数据库查询集成| 05_票务代理服务器多类型动态SQL生成与结果友好格式化| 06_基于Streamlit开发A2A多代理实时交互前端客户端
01_LLM 路由服务器(意图识别)| 02_天气代理服务器(查询天气数据库)| 03_票务代理服务器(查询票务数据库)| 04_MCP 工具服务器(数据库接口)| 05_数据采集脚本| 06_Streamlit 前端客户端

大型ToC企业中的客服团队往往是人力外包,对公司业务细节的了解程度不够,需要和产研团队多次沟通才能完成一次工单的处理,效率低下。 同时,随着AI的发展,工单的处理也可以基于大模型+RAG+funcation call能力进行提效,部分工单自动处理,从而节省部分客服人力资源。 本系统结合大模型能力,融合多种AI技术(RAG+多Agent+MCP)等,结合Kafka消息队列、PostgreSQL向量检索和Docker容器化部署,完成大型企业工单的判定、处理、建议与知识库实时迭代等全流程流转闭环,解决传统客服流程低效问题。
01_能够掌握企业级智能工单系统架构设计 02_实现基于规则过滤、查询改写、意图识别的全流程自动化处理 03_掌握具备复杂业务场景下多智能体系统的开发与运维能力。
01_使用无侵入的方式实时处理业务系统数据的解决方案| 02_实现企业私有化数据脱敏的解决方案| 03_实现基于多层模型实现复杂分类的解决方案| 04_实现基于RAG+MCP调用实现融合知识库+API的上下文工程的解决方案| 05_实现动态更新知识库的解决方案| 06_实现docker镜像构建和服务器部署的企业部署解决方案
01_项目冷启动阶段,基于大模型 + NLP算法,完成工单数据的清洗和工单、业务知识库的搭建(PG),工单会进行脱敏| 02_消费工单的Kafka消息队列数据,并基于规则过滤出来需要处理的工单| 03_实现query改写,提高检索内容的准确性,对PG进行检索时采用上下文+向量混合检索的方式,结合重排序模型实现查询内容的准确性| 04_实现意图识别和槽位填充, 基于用户的query基于MCP协议执行funcation call,在上下文中补充用户的实时数据作为上下文信息| 05_实现知识库实时迭代, 实现知识库数据实时更新,保证内容是最新的| 06_Docker镜像的构建和生产环境docker-compose模式部署
课时:5天 技术点:80项 测验:1次 学习方式:线下面授
01_能够理解 Transformer 的注意力机制与架构设计,并掌握基于 Transformer 的翻译任务开发技能| 02_能够使用 Hugging Face 库对预训练模型进行全量微调,完成特定 NLP 任务| 03_能够理解主流大模型的架构特性与预训练原理,掌握为微调任务选择合适模型的能力
1. 大模型Transformer架构该模块主要学习大模型Transformer架构,包含以下技术点:
01_词向量(Word Embedding)| 02_大模型Transformer架构的注意力机制 | 03_大模型Transformer架构(encoder、decoder、encoder+decoder)| 04_大模型Transformer翻译任务实战
2. 大模型迁移学习该部分主要学习大模型迁移学习,包含以下技术点:
01_迁移学习的预训练模型和微调阶段| 02_NLP中的常用预训练模型(BERT、GPT-1、GPT-2)| 03_Hugging Face预训练模型仓库| 04_Huggingface Transformers库使用(提供了NLP领域预训练语言模型结构模型和调用框架)| 05_基于微调方式实现中文分类、中文填空、句子关系等任务
3. 大模型主流模型运行机制该部分主要学习大模型主流模型运行机制,包含以下技术点:
01_GPT/DeepSeek/QWen基础| 02_GPT/DeepSeek/QWen架构变化| 03_GPT/DeepSeek/QWen的预训练任务| 04_基于DeepSeek/QWen预训练+微调任务实战
课时:5天学习方式:线下面授
【LoRA微调】微博文本信息抽取项目
【QLoRA微调】QWen微调文本摘要项目
基于中医药知识图谱项目

项目基于 Qwen/DeepSeek,通过 LoRA 和 P-Tuning 实现微博文本信息抽取+文本分类的多任务,通过一个大模型同时解决多种任务开发和应用。
01_了解和掌握大语言模型的基本原理和架构,特别是ChatGLM-6B模型的结构和工作机制掌握大模型LoRA微调技术,通过微调预训练的大模型来适应特定任务的需求| 02_掌握大模型P-Tuning微调技术,对大模型进行高效的参数调整,增强其在特定任务上的表现| 03_理解和应用多任务学习的概念,通过一个模型同时解决文本信息抽取和文本分类两种任务,提高模型的综合能力和应用效率| 04_掌握文本信息抽取技术,从非结构化的文本数据中提取有价值的信息,如实体、关系、事件等| 05_学习文本分类的基本原理和方法,掌握如何将文本数据按照预定义的类别进行归类通过Flask框架,学习如何开发和部署API接口,使模型能够通过网络服务被访问和使用
01_联合任务数据预处理适配模型训练的解决方案| 02_实现ChatGLM-6B+LoRA训练的解决方案| 03_实现ChatGLM-6B+P-Tuning训练的解决方案| 04_基于Flask框架实现模型API接口开发的解决方案
01_理解信息抽取任务以及文本分类的业务意义及应用场景| 02_数据预处理:修改数据格式适配大模型训练、数据张量的转换等| 03_Qwen/DeepSeek模型解析,LoRA方法讲解、P-Tuning方法解析| 04_基于Qwen/DeepSeek+LoRA方法实现模型的训练和评估| 05_基于Qwen/DeepSeek+P-Tuning方法实现模型的训练和评估| 06_基于Flask框架开发API接口,实现模型线上应用

项目以QWen模型为核心,借助DeepSpeed框架实现训练过程的加速优化。同时采用了GPTQ和QLoRA技术对模型进行量化处理,旨在进一步提升模型的推理速度。最终,通过Vllm平台完成了模型的部署,实现了对文本中关键信息的自动化抽取,完成信息抽取的任务。
01_掌握 QLoRA 量化微调与并行计算技术| 02_能够完成文本摘要模型的高效训练与部署
01_大模型并行计算解决方案| 02_大模型量化解决方案| 03_大模型部署解决方案| 04_大模型推理优化解决方案
01_数据集处理、模型构建、模型训练、模型预测| 02_大模型并行计算:DeepSpeed,数据并行、流水线并行、模型并行| 03_大模型量化:训练量化方法QLoRA,训练后量化方法GPTQ| 04_模型部署和推理优化框架:vLLM和oLLAMA

“草本通” 项目致力于解决中医药知识难以理解、碎片化严重、检索效率低 等问题,通过爬虫、DeepSeek+LangChain实体抽取、Neo4j图谱构建与LangGraph多智能体协同,打造一个可理解、可对话、可传播、可拓展 的智能知识服务平台。系统融合多种AI技术,支持从数据采集到语义问答、图谱构建、再到内容生成与平台发布的完整AI闭环。
01_能够掌握知识图谱构建、多智能体流程调度及生成式应用开发| 02_能够具备垂直领域知识智能化平台的搭建能力
01_多源中医药数据爬取与联合任务数据预处理适配知识图谱构建的解决方案| 02_基于 Neo4j + FAISS 的中医药知识图谱检索增强(RAG)解决方案| 03_基于 LangGraph 的中医药智能问答与多意图工作流编排解决方案| 04_基于 FastAPI 实现 LangGraph 智能体流式 API 接口开发的解决方案| 05_基于LamaFactory微调大模型进行实体关系生成的解决方案
01_利用爬虫自动采集中药、方剂、功效、症状、疾病等原始文本| 02_使用大语言模型(DeepSeek)+ LangChain 进行实体与关系抽取| 03_构建 Neo4j 图数据库与 Faiss 向量检索双引擎,实现结构化查询与语义匹配| 04_基于 LangGraph 搭建多智能体协同系统,管理复杂问答流程| 05_提供基于 Streamlit 的网页端交互式问答界面| 06_自动生成小红书风格图文内容,并实现一键发布,实现从“知识获取”到“内容传播”的闭环
课时:6天 技术点:70项 测验:0次 学习方式:线下面授
01_能够掌握 CNN、ResNet、Yolo 及分割算法的核心原理| 02_能够具备开发图像分类与目标检测应用的能力
1. CV图像分析该部分主要学习CV图像分析核心知识,包含以下技术点:
01_CNN| 02_ResNet原理| 03_Yolo V系列算法| 04_图像分类与分割(Unet、MaskRCNN)
课时:6天技术点:80项测验:0次学习方式:线下面授
01_能够理解 AIGC 与 Diffusion 模型原理| 02_掌握 Stable Diffusion 的模型构建与微调| 03_能够完成图像生成小程序的开发

项目基于Stable Diffusion,利用稳定扩散过程,通过逐渐模糊和清晰化图像来实现图像生成的过程。这种方法在图像生成领域具有广泛的应用,项目可扩展于艺术创作、虚拟场景生成、数据增强等。
01_图像生成的常见解决方案| 02_文图匹配的解决方案| 03_扩散模型噪声去除的解决方案| 04_潜在空间扩散模型的解决方案| 05_扩散模型训练的解决方案| 06_小程序搭建的解决方案
01_AIGC的详解:AIGC简介,类型,应用场景,产品形态| 02_图像生成算法:GAN,VAE,Diffusion,DALLe,imagen| 03_StableDiffusion的详解:Diffusion,latent diffusion;satble diffusion| 04_stablediffusion实践:模型构建,模型训练,lora,dreambooth,图像生成效果| 05_图像生成小程序搭建:基于stablediffusion构建图像生成的小程序
课程名称:主要针对:主要使用开发工具:
教师录取率<3%,从源头把控师资,带你过关斩将掌握每一个知识点
用数据驱动教学,贯通教/学/练/测/评,为每一位学员私人定制学习计划和就业服务








学前入学多维测评
学前目标导向式学习
学中随堂诊断纠错
学中阶段效果测评
学后在线作业试题库
学后问答社区查漏补缺
保障BI报表数据呈现
就业面试指导就业分析
就业流程
全信息化处理
学员能力
雷达图分析
定制个性化
就业服务
技术面试题
讲解
就业指导课
面试项目分析
HR面试攻略
模拟企业
真实面试
专业简历指导
面试复盘辅导
风险预警
企业黑名单提醒
老学员毕业后即可加入传智汇精英社区,持续助力学员职场发展

传智教育旗下IT互联网精英社区,以汇聚互联网前沿技术为核心,以传递、分享为己任,联合经纬创投、创新工场、京东人工智能、华为等众多关注互联网的知名机构及企业、行业大咖,共同研究中国互联网深度融合、跨界渗透、整合汇聚、相互促进的信息化资源共享平台。
行业沙龙

高端人脉

职场资源

技术研习

9970元/月平均薪资
15900元/月最高薪资
100%就业率
58人月薪过万
*学员就业信息统计数据为数据库中实时调取的真实相关数据,非广告宣传
江苏传智播客教育科技股份有限公司 版权所有Copyright 2006-2024, All Rights Reserved 苏ICP备16007882号-1 营业执照 增值电信业务经营许可证 出版物经营许可证  苏公网安备 32132202000574号
苏公网安备 32132202000574号





