
 北京昌平
北京昌平 北京顺义
北京顺义 上海
上海 广州
广州 深圳
深圳 武汉
武汉 郑州
郑州 西安
西安 长沙
长沙 济南
济南 南京
南京 杭州
杭州 成都
成都










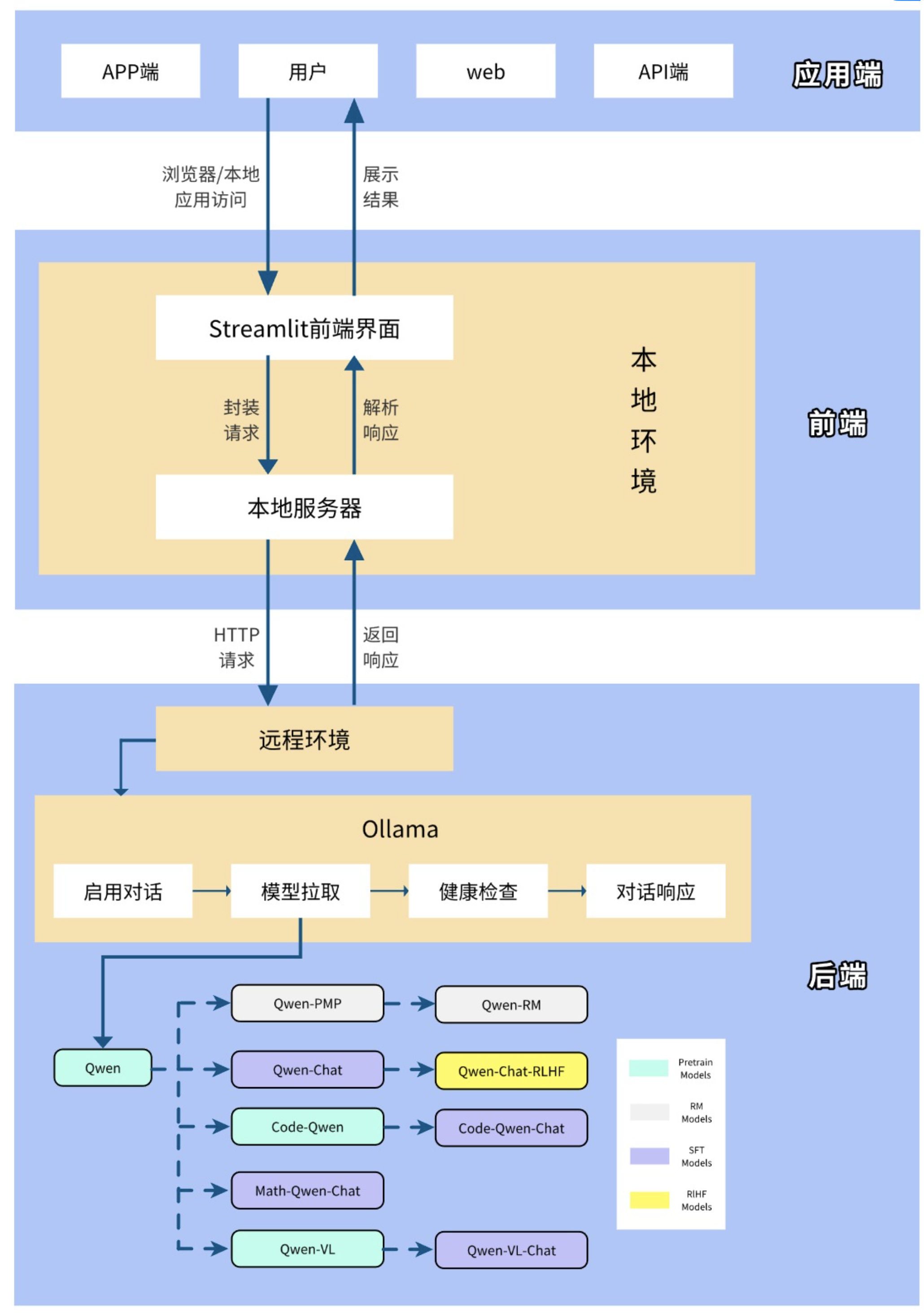
DeepSeek私有化部署与聊天机器人搭建
项目基于Ollama私有化部署DeepSeek R1:8b模型,基于Docker结合Dify大模型应用开发平台构建可视化聊天界面,并搭建人工智能技术答疑场景的RAG系统,通过集成DeepSeek构建专属AI助手,解决模型幻觉问题。并且通过DeepSeek构建企业应用智能体。项目实现了AI大模型从私有化部署、聊天机器人搭建、RAG系统到Agent智能体构建。
可掌握的核心能力
1.掌握大模型部署方案
2.掌握Dify大模型应用开发平台使用
3.掌握基于Dify构建RAG系统 4.掌握基于CrewAI的Agent智能体构建
技术亮点
大模型私有化部署方案
Dify搭建聊天机器人
搭建本地知识库解决方案
大模型智能体解决方案
技术架构图
蜂窝头条投满分项目
蜂窝头条投满分项目是结合今日头条真实场景下的海量数据, 快速搭建随机森林和FastText的基线模型, 以验证商业化落地的可行性. 更多聚焦在深度学习的优化方法上, 搭建基于BERT的初版微调模型, 应用量化,剪枝,预训练模型微调,知识蒸馏等多种手段,反复迭代,反复优化模型的离线效果,在线效果。
可掌握的核心能力
1. 基于大规模业务留存数据构建快速文本分类系统
2. 基于推荐系统内部分频道投递的需求,
快速搭建短文本精准分类投递的模型
3. 基于随机森林和FastText搭建快速基线模型, 验证业务通道的能力
4. 基于BERT的迁移学习优化模型搭建的能力
5. 实现神经网络量化的优化与测试
6. 实现神经网络剪枝的优化与测试
7. 实现神经网络知识蒸馏的优化与测试
8. 更多主流预训练模型的优化与深度模型剖析
9. BERT模型在生成式任务和工程优化上的深入扩展
技术亮点
海量文本快速分类基线模型解决方案
基于预训练模型优化的解决方案
模型量化优化的解决方案
模型剪枝优化的解决方案
模型知识蒸馏优化的解决方案
主流迁移学习模型微调优化的解决方案
技术架构图

医疗知识图谱项目
医疗知识图谱项目是一款基于知识图谱的多功能问答机器人项目, 主要解决当前NLP领域中大规模知识图谱构建的问题和图谱落地的问题.知识图谱的构建主要分为知识构建和知识存储两大子系统.知识构建部分将重点完成命名实体识别和关系抽取的模型搭建与优化,深入解析并实现Casrel模型实现文本自动关系抽取的实现.并深入解析实体对齐和实体消歧的NLP难题解决方案, 深度结合工业界流行的解决方案. 最终呈现一个基于知识图谱的问答机器人。
可掌握的核心能力
1.图谱全流程管理 —— 掌握从数据获取到图谱构建的全生命周期
2.图谱理论与应用 —— 熟悉知识图谱定义、类型及多领域应用
3.Neo4j 技术 —— 精通图数据库的存储与查询优化
4.深度学习 NER —— 掌握 CRF、BERT、BiLSTM+CRF 等实体识别方法
5.多样化关系抽取 —— 熟练运用规则、Pipeline 与 Casrel 模型提取关系
6.知识融合与消歧 —— 掌握实体消歧和关系对齐技术
7.医疗问答开发 —— 实现意图识别与对话管理的智能问答系统
8.NLP 语义处理 —— 精通自然语言理解(NLU)与生成(NLG)
9.模型工程化 —— 掌握数据预处理与模型训练全流程
10.垂直领域图谱 —— 构建医疗、商业等领域的定制知识图谱
技术亮点
智能搜索优化 ——
利用语义理解与实体关联提升搜索准确性(图谱智能搜索)
医疗诊断与研发 —— 构建医疗知识图谱,支持疾病诊断及药物研发
高效知识存储与查询 —— 基于 Neo4j 存储与查询 SPO 三元组数据
智能问答系统 —— 结合 NLU 与知识图谱实现精准问答
异构数据整合 —— 通过实体抽取融合多源数据构建一致知识图谱
技术架构图

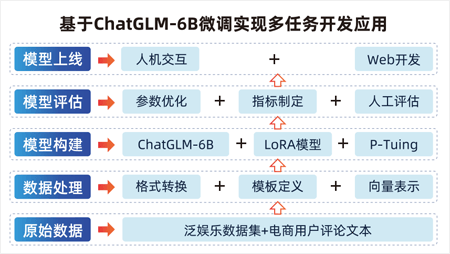
微博文本信息抽取项目
基于ChatGLM/QWen+LoRA微调实现微博文本信 息抽取+文本分类的多任务,通过一个大模型 同时解决多种任务开发和应用,项目基于LLM 进行混合任务开发应用的实现,利用 ChatGLM/QWen大模型进行P-Tuning微调的方 式,基于Flask框架实现API接口开发和应用。
可掌握的核心能力
1.了解和掌握大语言模型的基本原理和架构,特别是ChatGLM/QWen模型的结构和工作机制
2.掌握大模型LoRA微调技术,通过微调预训练的大模型来适应特定任务的需求
3.掌握大模型P-Tuning微调技术,对大模型进行高效的参数调整,增强其在特定任务上的表现。
4.理解和应用多任务学习的概念,通过一个模型同时解决文本信息抽取和文本分类两种任务,提高模型的综合能力和应用效率
5.掌握文本信息抽取技术,从非结构化的文本数据中提取有价值的信息,如实体、关系、事件等
6.学习文本分类的基本原理和方法,掌握如何将文本数据按照预定义的类别进行归类
7.通过Flask框架,学习如何开发和部署API接口,使模型能够通过网络服务被访问和使用
技术亮点
联合任务数据预处理适配模型训练的解决方案
实现ChatGLM/QWen+LoRA训练的解决方案
实现ChatGLM/QWen+P-Tuning训练的解决方案
基于Flask框架实现模型API接口开发的解决方案
技术架构图
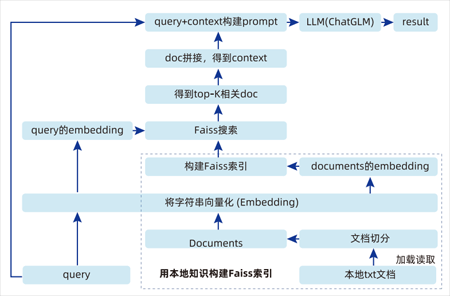
物流信息咨询智能问答项目
项目基于LangChain+ChatGLM/QWen实现电商物流 本地知识库问答机器人搭建,让模型根据本地信 息进行准确回答,解决大模型的“幻觉”问题, 实现精准问答。通过项目皆在掌握LangChain工 具的基本使用方式,理解向量知识库以及实现知 识库的技术原理,快速构建检索增强生成 (RAG)系统
可掌握的核心能力
1.掌握LangChain工具的基本使用方法,了解如何通过LangChain构建和管理语言模型应用
2.熟悉ChatGLM/QWen模型的应用,了解如何将大语言模型与本地知识库结合,实现高效准确的问答功能
3.理解向量知识库的基本概念和技术原理,掌握如何构建和使用向量知识库来存储和检索知识信息
4.掌握知识库的构建方法,从数据采集、处理到存储,学习如何将电商物流相关信息整合到知识库中
5.理解RAG系统的基本原理和实现方法,学习如何结合检索和生成技术,提升问答系统的准确性和实用性
6.从零开始搭建一个问答机器人,掌握整个系统的设计、实现和部署过程
技术亮点
LangChain工具使用介绍解决方案
ChatGLM/QWen模型集成到问答系统中的解决方案
向量知识库的构建和检索的解决方案
搭建RAG系统的解决方案
技术架构图
基于StableDiffusion的图像生成项目
基于Stable Diffusion的图像生成项目是一种基于深度学习的图像生成方法,旨在生成高质量、逼真的图像。该项目利用稳定扩散过程,通过逐渐模糊和清晰化图像来实现图像生成的过程。这种方法在图像生成领域具有广泛的应用,包括艺术创作、虚拟场景生成、数据增强等。
可掌握的核心能力
1.知道AIGC是什么,理解AIGC的产品形态
2.知道图像生成的常用方式
3.理解GAN ,VAE,Diffusion的思想
4.掌握StableDiffusion的网络结构
5.理解文图匹配的clip模型
6.理解Unet网络和采样算法的作用
7.知道VAE解码器的作用
8.知道drembooth和lora的模型训练方式
9.能够搭建图像生成的小程序
技术亮点
图像生成的常见解决方案
文图匹配的解决方案
扩散模型噪声去除的解决方案
潜在空间扩散模型的解决方案
扩散模型训练的解决方案
小程序搭建的解决方案
技术架构图

EduRAG智慧问答系统
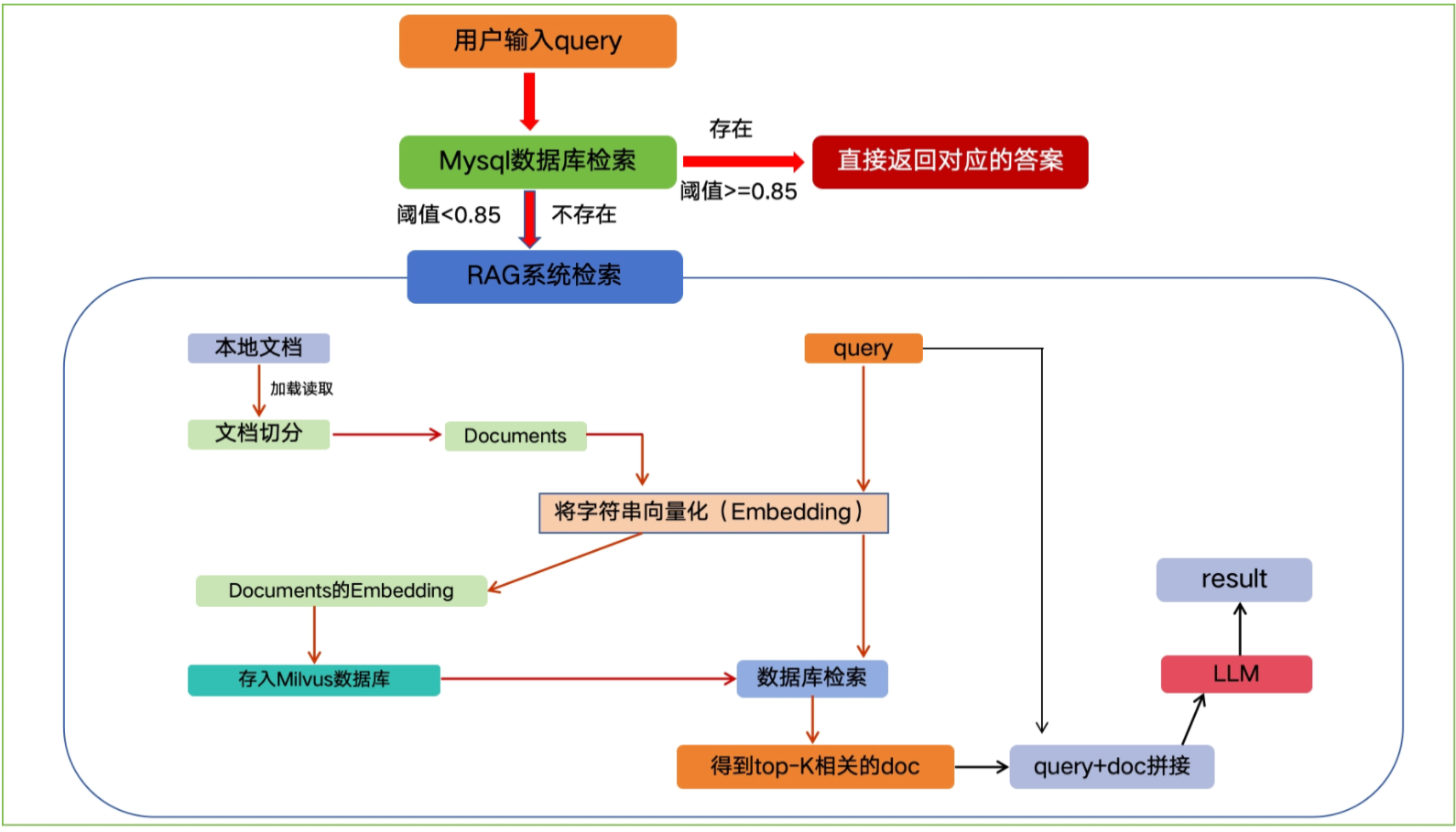
EduRAG 是一个企业级智能问答系统,专为教育场景设计,整合了基于 MySQL 的快速 FAQ 检索和基于 RAG(Retrieval-Augmented Generation)的复杂问题处理能力。系统通过结合 MySQL 数据库的高效查询和 Milvus 向量数据库的语义检索,实现了从常见问题到专业咨询的全方位问答支持。系统支持多来源过滤(如 AI、Java、测试、运维、大数据),并通过 Redis 缓存优化性能,使用 LLM 提供高质量答案生成。
可掌握的核心能力
1.了解LangChain基本概念、明确LangChain主要组件的作用、了解LangChain常见的使用场景
2.掌握基于LangChain+ChatGLM-6B模型实现本地知识库的问答实现原理+过程
3.RAG 系统开发与优化:掌握从数据分片到答案生成的 RAG 全流程,熟练应用
HyDE、子查询等检索增强策略提升系统性能
4.大模型应用实践:能够集成 LLM(如 OllamaLLM)并设计高效
Prompt,解决知识问答中的业务定制化需求
5.智能查询路由设计:实现规则、相似度和 LLM
三层路由,精准分发查询并优化复杂意图识别效率
6.后端服务与前端开发:使用 FastAPI 开发高并发 API 并通过 Gradio
构建交互界面,满足企业级服务与用户体验要求
7.数据处理与多源集成:熟练处理结构化与非结构化数据,结合 MySQL
和向量搜索打造高效知识检索系统
8.企业级问题解决能力:通过日志调试和高并发设计,具备定制化开发与性能优化的实战技能,适配智能客服等场景
技术亮点
数据库查询优化:BM25 + Redis 缓存
语义检索:Milvus 混合向量检索
查询分类:BERT 分类器
动态检索策略:LLM 驱动的策略选择(直接检索、HyDE、子查询、回溯)
答案生成:LLM + RAG 提示模板
性能优化:Redis 缓存 + 模块化设计
日志与监控:统一日志系统(logging)
配置管理:ConfigParser + config.ini
技术架构图