
全国中心













 AI智能应用开发
AI智能应用开发 AI大模型开发
AI大模型开发 AI鸿蒙开发
AI鸿蒙开发 AI嵌入式+
AI嵌入式+ AI大数据开发
AI大数据开发 AI运维
AI运维 AI测试
AI测试 跨境电商运营
跨境电商运营 AI设计
AI设计 AI视频创作运营
AI视频创作运营
免费领取黑马程序员AI通道专属星级课程资料

更新时间:2021-12-02 来源:黑马程序员 浏览量:
Flume的核心角色是Agent,通过Agent可以从其他服务中采集数据,并通过内部event流的形式传输到Sink,并根据需求最终向下一个Agent传输或者进行集中式存储。
在实际开发中,Flume需要采集数据的类型多种多样,同时还会进行不同的中间操作,所以根据具体需求,可以将Flume日志采集系统分为简单结构和复杂结构。
1. 简单结构
当需要采集数据的生产源比较单一、简单的时候,可以直接使用一个Agent来进行数据采集并最终存储,结构如Flume基本架构,如下图所示。
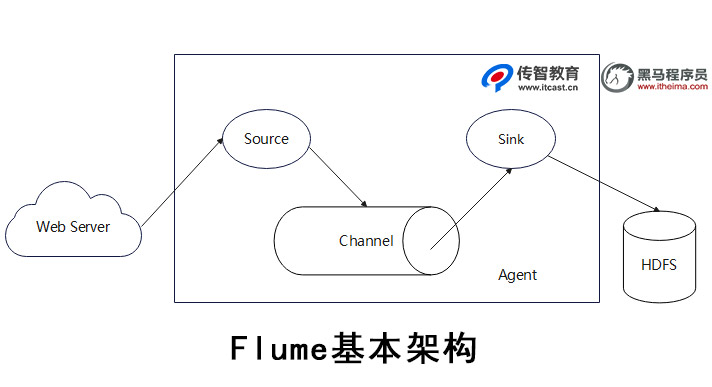
2. 复杂结构
有时候需要采集数据的数据源分布在不同的服务器上,使用一个Agent进行数据采集不再适用,这时就可以根据业务需求部署多个Agent进行数据采集并最终存储,结构如下图所示。
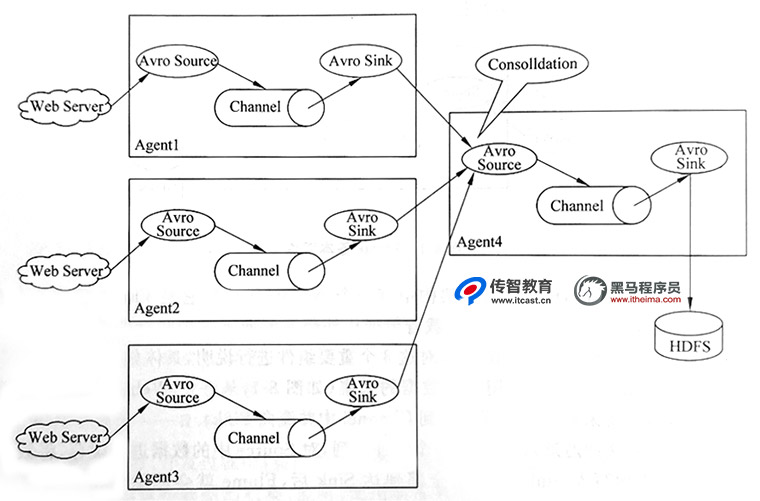
从图2可以看出,对每一个需要收集数据的Web服务端都搭建了一个Agent进行数据采集,接着再将这多个Agent中的数据作为下一个Agent的Source进行采集并最终集中存储到HDFS中。
除此之外,在开发中还有可能遇到从同一个服务端采集数据,然后通过多路复用流分别传输并存储到不同目的地的情况,结构如图3所示。
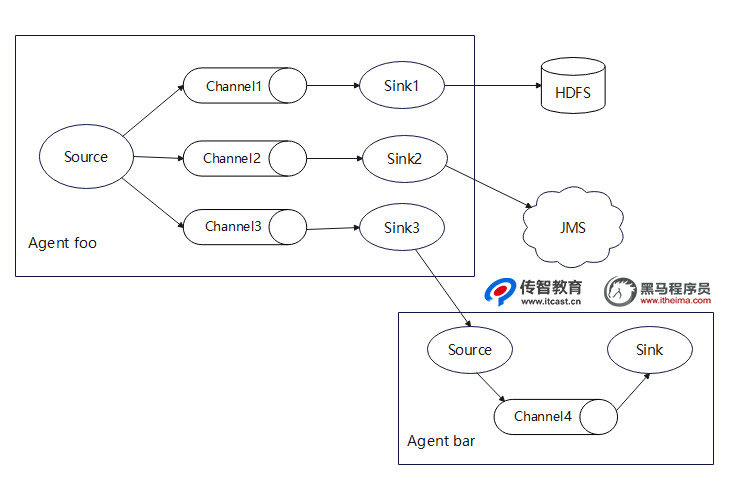
从图3可以看出,根据具体需求,将一个Agent采集的数据通过不同的Channel分别流向了不同的Sink,然后再进行下一阶段的传输或存储(如图3所示,将多个Sink数据分别进行了HDFS集中式存储、作为JMS消息服务、作为另一个Agent的Source)。
猜你喜欢:




















.jpg)